 Algoritmos de diff
Algoritmos de diff
Algoritmos de diff
Algoritmos de diff
Imagino que muitos leitores já utilizaram o aplicativo diff, ou já lidaram com "patches" ou "commits" do Git cujo conteúdo é algo semelhante a isto:
--- Analytics.java.old 2016-04-03 00:07:40.000000000 -0300
+++ Analytics.java 2016-04-03 00:07:50.000000000 -0300
@@ -78,15 +78,13 @@
in_flight = true;
- JsonObjectRequest req = new JsonObjectRequest(Request.POST,
+ JsonObjectRequest rez = new JsonObjectRequest(Request.GET,
new Response.Listener<JSONObject>() {
@Override
public void onResponse(JSONObject response) {
O arquivo acima é um script de edição: uma lista de instruções que, aplicada ao arquivo original Analytics.java.old, torna-o igual ao arquivo Analytics.java. Fora os detalhes fantasmagóricos como as @@ e os números, é fácil ver que o script substitui uma linha terminada em POST por outra que termina em GET.
Existem diversos formatos de "diff". O formato acima é o "Universal" cuja descrição pode ser encontrada aqui e é o mais utilizado por estes dias. Certamente o uso generalizado do Git consolidou essa dianteira, e levou muita gente de fora do mundo Unix a ficar conhecendo os "diffs", por bem ou por mal.
Apesar de ter curiosidade sobre o algoritmo (ou algoritmos) do diff, nunca pesquisei mais a fundo, até precisar de um algoritmo análogo, porém numa situação em que usar o diff mesmo não seria viável.
Explico: tenho um conjunto de testes de um aplicativo. O framework de teste (caseiro) armazena um "filminho" com alguns dados essenciais, durante a execução de cada teste. Tornou-se importante detectar mudanças de comportamento durante a execução do teste, mesmo que o resultado final seja igual e válido. Digamos que, durante o teste, aconteça A,B,C,D,E. Se numa execução posterior acontecer A,D,C,B,E, tem de haver um bom motivo.
Precisei de uma ferramenta ergonômica que evidenciasse as diferenças, a fim de tratá-las. Gerar dois arquivos de texto e fazer diff não é suficiente, pois há muitos dados do "filminho", como timestamps, que não devem ser considerados como diferenças. Em resumo, por motivos presentes e futuros, resolvi implementar um "diff" específico para esta massa de dados.
Se você deseja apenas uma implementação do melhor algoritmo disponível, e não quer saber dos detalhes sórdidos, baixe e abra este Zip, e procure pelo script diff_myers.py. Esse script implementa o algoritmo Myers, utilizado por praticamente todos os utilitários (diff, Git, etc.).
O caminho racional seria usar um módulo pronto como este, mas que graça teria? :) Tentando reinventar a roda, cheguei no seguinte algoritmo, em Python-pseudocódigo:
# A e B são matrizes contendo elementos a serem diff'ados
# Corta o "rabo": parte final que coincide
while A and B and A[-1] == B[-1]:
A.pop()
B.pop()
while A or B:
# Corta a "cabeça": parte inicial que coincide
while A and B and A[0] == B[0]:
A.pop(0)
B.pop(0)
minus = len(A)
plus = len(B)
cost = minus + plus
# Acha a próxima coincidência com menos "custo"
for i in range(0, len(A)):
for j in range(0, len(B)):
new_cost = i + j
if new_cost > cost:
break
if A[i] == B[j]:
if new_cost < cost:
cost = new_cost
minus = i
plus = j
break
# Transforma a lista em script de edição
edita("-", A[0:i])
edita("+", B[0:j])
A = A[i:]
B = B[j:]
(Uma implementação funcional pode ser obtida aqui. O arquivo correspondente no Zip é diff_naive.py. Essas implementações de brinquedo comparam duas strings passadas na linha de comando, mas o algoritmo é facilmente adaptável para comparar linhas de arquivos.)
A estratégia do algoritmo é: ir cortando a "cabeça", ou seja, a parte inicial que coincide; e então procurar a próxima posição onde algum elemento coincide. Pode haver diversas coincidências, então eu procuro a de menor "custo", ou seja, aquela que se alcança com o menor número de edições.
Por incrível que pareça, o algoritmo funcionou bem, e ainda está em uso na ferramenta de teste, porque foi perfeitamente suficiente.
Um primeiro problema é o tempo de execução O(mn) — diffar duas strings de 10K implica em 100M ciclos potenciais. Na prática, não vai ser tão ruim porque em geral comparamos strings meio semelhantes, o que reduz muito o esforço. Uma vantagem do algoritmo "bobo" é não gastar nenhuma memória, fora um punhado de variáveis.
O maior problema é gerar scripts de edição sub-ótimos, ou seja, maiores do que o estritamente necessário. Eis um caso que "enganou" o algoritmo:
./diff_naive.py _C_D_E _CD_E_ _ C +D _ -D +E _ -E
A solução encontrada tem 4 edições, mas poderia ter apenas 2. Qualquer um pode ver que bastaria mudar um underscore de lugar para transformar _C_D_E em _CD_E_.
O algoritmo bobo se perde porque o elemento underscore é muito comum, e há muitas coincidências "baratas" com ele. Se estivéssemos comparando dois arquivos de código-fonte, as linhas comuns que poderiam atrapalhar o algoritmo seriam as linhas vazias, linhas só com fecha-chaves, etc.
Esse é um bom exemplo de algoritmo "cobiçoso" (greedy): ele toma decisões de curto prazo. Às vezes esse tipo de algoritmo é perfeito, mas não neste caso.
Por outro lado, o algoritmo encontra facilmente soluções ótimas para strings com poucos elementos repetidos. Por exemplo, comparar ABCDE com BCDEXF não causa problemas, porque existe uma "ordem" intrínseca dos elementos. Procurar por C ou por BCDE dá no mesmo, só que procurar apenas por C é muito mais barato.
No meu caso de uso, onde a "string" é na verdade uma lista de estados do aplicativo durante a execução de um teste, praticamente não há estados repetidos — o que explica o bom desempenho.
Uma modificação fácil de fazer é "especular" recursivamente qual seria o custo dos próximos passos do algoritmo, simulando até o final do processo, e retornar o custo total para o chamador original. Até funciona, porém é extremamente custosa em processamento e consumo de pilha, então não serve para uso geral.
Também é possível fazer uma implementação sub-ótima de diff procurando por substrings em comum. O script diff_lcstr.py materializa essa ideia, usando recursão. Segue o pseudocódigo:
def lcstr(A, B): corte os elementos iniciais em comum corte os elementos finais em comum encontre a maior substring em comum "S" Se len(S) = 0: liste os elementos de A como "-" liste os elementos de B como "+" Encerrar lcstr(A[:A.indexOf(S)], B[:B.indexOf(S)]) lcstr(A[A.indexOf(S)+len(S):], B[B.indexOf(S)+len(S):])
O algoritmo acima acha a maior substring em comum, que obviamente não vai entrar no script de edições, e recursivamente procura substrings comuns nas "sobras" anteriores e posteriores, até não sobrar nada.
À primeira vista ele parece ser mais esperto que o algoritmo "bobo":
./diff_lcstr.py _C_D_E _CD_E_ _ C -_ D _ E +_
Mas ele também pode ser enganado, e chega a produzir resultados piores que o algoritmo "bobo":
./diff_naive.py _C_D_EFGH_ _CD_E_F_G_H_ _ C +D _ -D +E _ -E F +_ G +_ H _ /Users/epx $ ./diff_lcstr.py _C_D_EFGH_ _CD_E_F_G_H_ _ C -_ D _ E -F -G +_ +F +_ +G +_ H _ /Users/epx $ ./diff_myers.py _C_D_EFGH_ _CD_E_F_G_H_ _ C -_ D _ E +_ F +_ G +_ H _
Imagino que, em algumas situações, esse algoritmo possa gerar scripts de edição subjetivamente agradáveis, justamente porque ele procura preservar as maiores seqüências comuns. Mas é apenas uma hipótese que não testo neste artigo.
Em ciência da computação, o melhor script de edição é o mais curto possível. Um bom algoritmo de diff acha sempre o script mais curto, de preferência usando pouca CPU e pouca memória.
Há aplicações em que o "melhor" script de edição, subjetivamente falando, não é necessariamente o mais curto — principalmente quando um humano vai dar uma olhada no script. Por exemplo:
./diff_myers.py DILMA AECIO -D -I -L -M A +E +C +I +O
O script acima é "ótimo" por reaproveitar a letra A comum, gerando 8 alterações em vez de 10. Porém, subjetivamente, o melhor mesmo seria fazer -(DILMA) +(AECIO). Got the point? :)
A propósito, o Git implementa um comparador chamado Patience Diff com esse objetivo: gerar patches mais legíveis e bonitos, para serem lidos por humanos.
Nesse ponto, voltamos a adotar a definição que "o melhor diff é o mais curto". O problema do diff equivale a outro problema de ciência da computação: encontrar a subseqüência comum mais longa, conhecida como LCS.
A LCS é diferente da "maior substring comum" pois na LCS é permitido remover elementos. Por exemplo, a LCS de "_C_D_E" e "_CD_E_" é "_CDE", enquanto a maior substring comum é "D_E".
Por outro lado, LCS("AECIO","DILMA") só pode ser "A" ou "I", nesse caso as possíveis LCS coincidem com as substrings em comum. (O LCS não pode inverter elementos, então "IA" e "AI" não são soluções.)
Uma vez encontrada a LCS, basta reinterpretar as deleções como um script de edição. As deleções na primeira string viram "-", as deleções na segunda string viram "+". Basta constatar o que acontece com as strings-cobaia:
./diff_myers.py _C_D_E _CD_E_ _ C -_ D _ E +_
Para os fins do resto do artigo, vou substituir os underscores por "X", o que não muda muito o resultado:
./diff_myers.py xCxDxE xCDxEx x C -x D x E +x
O processo de encontrar a LCS pode ser modelado como um grafo:
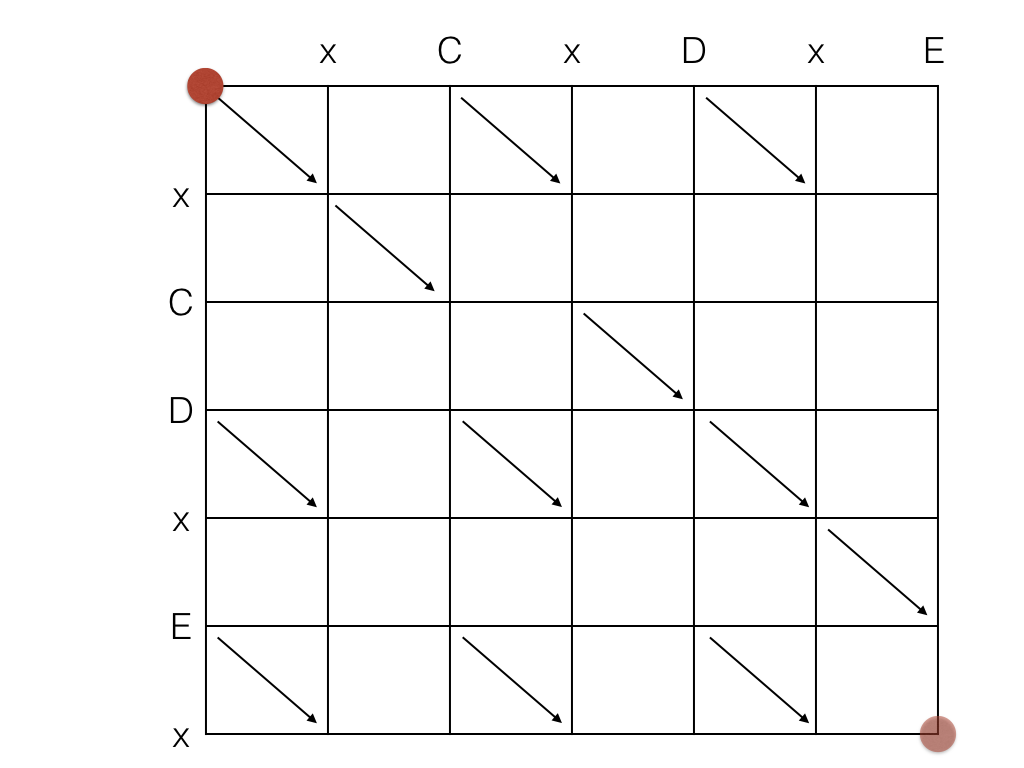
O objetivo do "jogo" é mover o ponto vermelho do canto superior esquerdo para o canto inferior direito, fazendo o menor número possível de movimentos. O ponto pode andar para baixo, para a direita, e também na diagonal quando há uma diagonal disponível. O caminho mais curto corresponde à LCS.
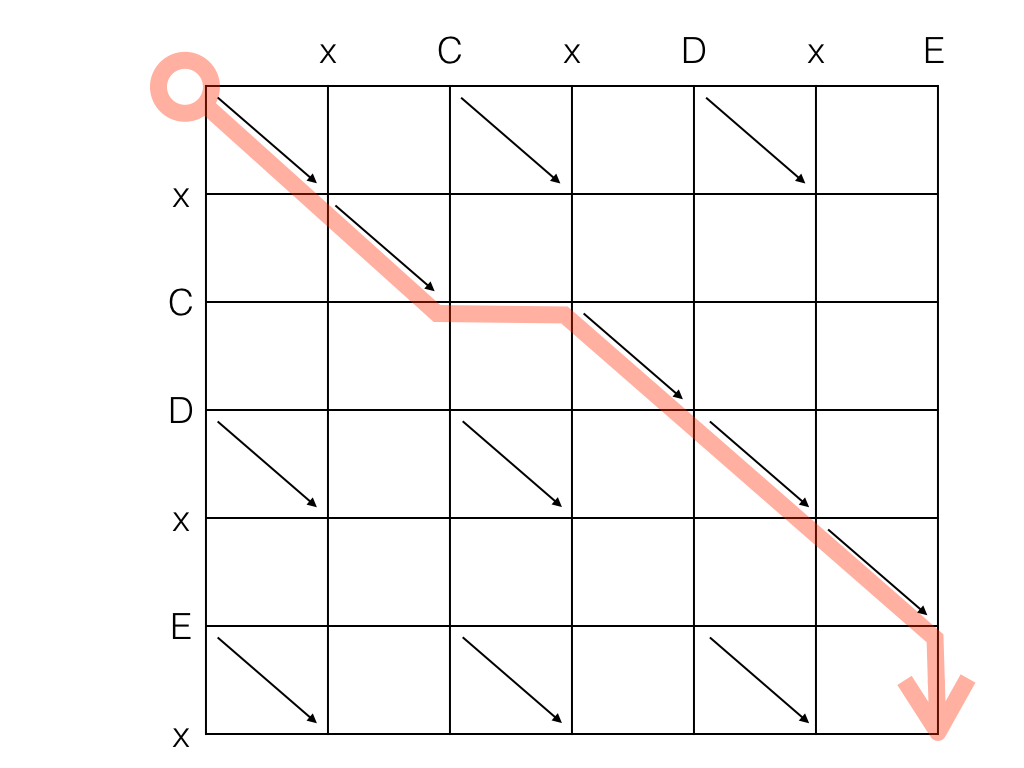
O "comprimento" do caminho, que os artigos científicos chamam de D e eu chamei de "custo" no outro algoritmo, é a soma dos movimentos verticais e horizontais. Os movimentos diagonais não contam, então o caminho mais curto é o que inclui o maior número possível de diagonais. Por outro lado, o caminho mais longo nunca poderá ser maior que len(A) + len(B). O exemplo acima tem custo ou D=2.
A string "velha" (A) está na linha horizontal. A string "nova" (B) está na linha vertical. As diagonais representam elementos em comum entre as duas strings. Cada movimento para a direita representa uma deleção na string A (que será interpretada como uma deleção no script de edição). Cada movimento para baixo representa uma deleção na string B (que será interpretada como uma inserção no script de edição).
Podemos agora representar, e analisar, o caminho que o algoritmo "bobo" tinha encontrado:
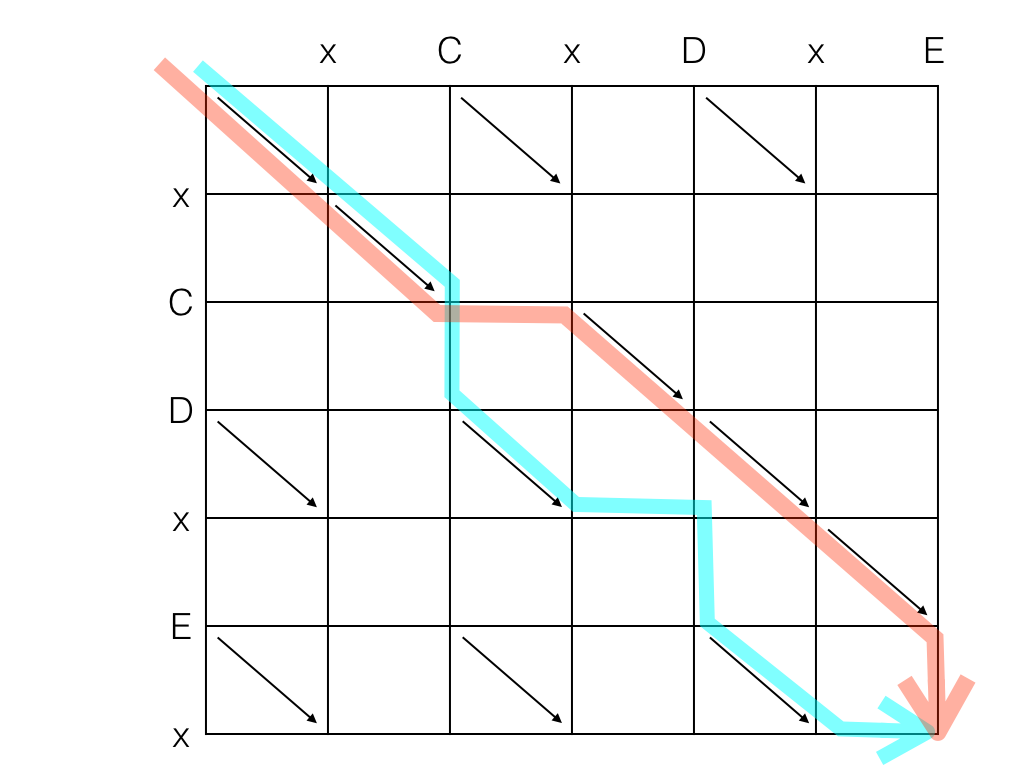
Como é um exemplo muito simples, houve uma dose de falta de sorte: na coordenada (2,2), o algoritmo "bobo" escolheu ir para baixo em vez de ir para a direita, embora naquele ponto ambas as diagonais mais próximas estivessem à mesma distância. O algoritmo encarou ambas as opções como igualmente boas, só que não eram. Se adicionarmos caracteres à string A (por exemplo, fazendo-a "xCx____DxE") o algoritmo sempre tomará o caminho errado, mesmo num dia de sorte.
Com esse grafo, podemos ver como o algoritmo "bobo" funciona: ele procura a diagonal mais próxima, a partir do ponto onde ele está, sem olhar o que existe mais adiante.
Já o algoritmo baseado em substrings comuns procura sempre a seqüência mais longa de diagonais, o que no exemplo acima seria acertado, porém erraria feio se, por exemplo, houvesse uma seqüência de 2 diagonais no canto superior direito, e diagonais simples espalhadas pelo resto do grafo:
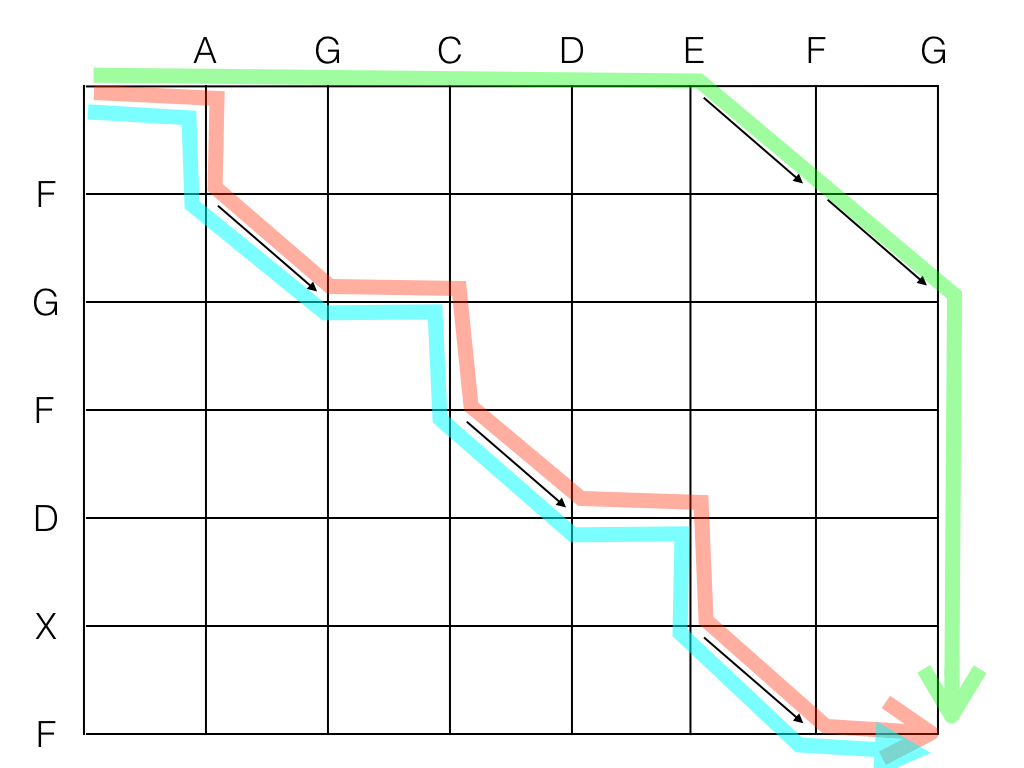
Nesse caso o algoritmo "bobo" andou na cola do caminho ótimo, porque procurar pela diagonal mais próxima era a coisa certa a fazer. Segue os scripts de edição correspondentes a cada um:
./diff_lcstr.py AGCDEFG FGFDXF Longest: FG -A -G -C -D -E F G +F +D +X +F ./diff_myers.py AGCDEFG FGFDXF -A +F G -C +F D -E +X F -G
Note que, apesar do segundo script de edição ser mais curto, o primeiro é consideravelmente mais legível para um ser humano. Muita gente diria que o primeiro é (subjetivamente) "melhor" que o segundo.
O melhor algoritmo conhecido apoia-se no fato de que o número de grandes diagonais no grafo LCS cresce linearmente, não quadraticamente.
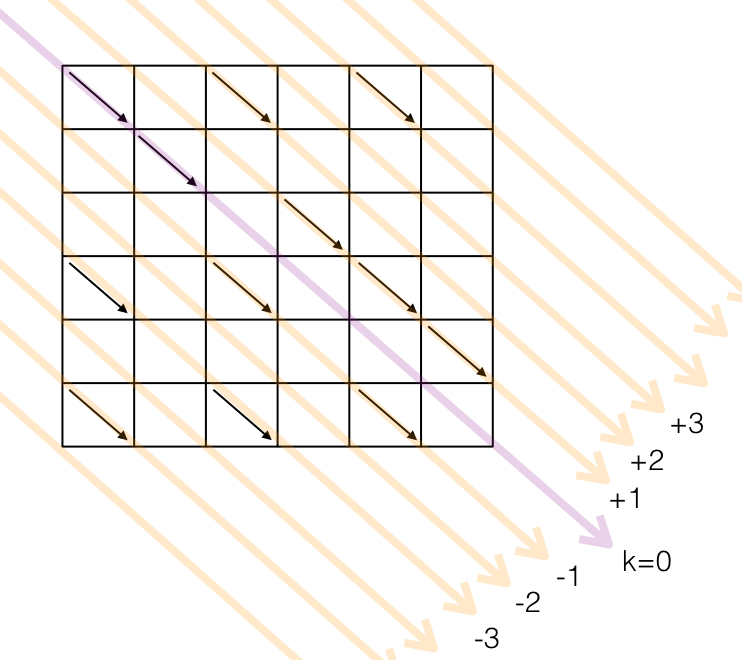
Na literatura, essas grandes diagonais são conhecidas por k e são numeradas, começando pela diagonal central k=0, números positivos para as diagonais superiores e negativos para as inferiores. Para um grafo NxM, não é preciso considerar mais que M+N diagonais.
O algoritmo cria diversos caminhos e vai estendendo os mesmos, "alimentando" cada um com um segmento horizontal ou vertical de cada vez, até um deles atingir o objetivo. A primeira preocupação é como armazenar todos esses caminhos na memória. O "pulo do gato" é que o número máximo deles nunca ultrapassa o número de grandes diagonais (M+N).
A figura a seguir ilustra como o algoritmo trabalha:
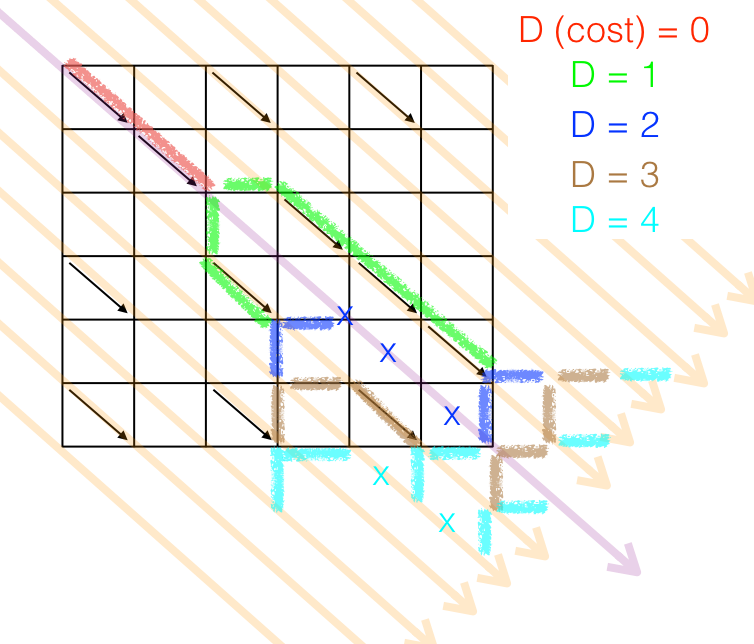
O grafo acima é o mesmo da comparação xCxDxE/xCDxEx. O "passo zero", em vermelho, não tem custo porque é a remoção da "cabeça" das duas strings, que coincidem. Só existe um caminho em k=0, e o algoritmo nem trabalhou ainda.
No passo 1 (verde), o algoritmo cria dois caminhos e "alimenta" cada um com uma edição. Um foi para a grande diagonal, k=1, o outro para k=-1. Ambos encontraram diagonais, que os fizeram avançar "de graça".
No passo 2 (azul escuro), os dois caminhos viram três. Porém não viram quatro — dois caminhos vão para a grande diagonal k=0, aí apenas o caminho mais promissor sobrevive. O outro é morto (vide os X azuis). Nesse ponto o algoritmo já pode parar, porque um caminho acaba de atingir o objetivo.
Se o grafo fosse maior, a extensão prosseguiria conforme os traços marrons (custo=3) e azul-turquesa (custo=4). Um aspecto explorado pelo algoritmo é que um caminho de custo D ocupa obrigatoriamente uma diagonal de número (-D, -D+2, ..., D-2, D). Então, a cada ciclo, apenas metade das grandes diagonais está na linha de frente.
O artigo original de Eugene Myers contém pseudocódigo e explica de forma muito mais rigorosa cada um desses detalhes. Se você comparar o script diff_myers.py com o artigo, vai ver que é praticamente uma cópia fiel — o artigo é amigável com os desenvolvedores, embora seja uma leitura bem pesada.
Um "problema" do algoritmo Myers é que ele apenas percorre e acha o melhor caminho sem armazenar os passos intermediários. Fica em aberto o problema de gerar o script de edição.
Na minha implementação (diff_myers.py) eu simplesmente vou armazenando o script de edição para cada caminho conforme o algoritmo prossegue, o que é fácil e simples, porém o uso de memória volta a ser quadrático, o que poderia ser proibitivo para algumas aplicações.
O utilitário diff do Unix e possivelmente todos os seus "descendentes espirituais", como o Git, usam uma interessante estratégia: executam o algoritmo a partir do início e também do final.
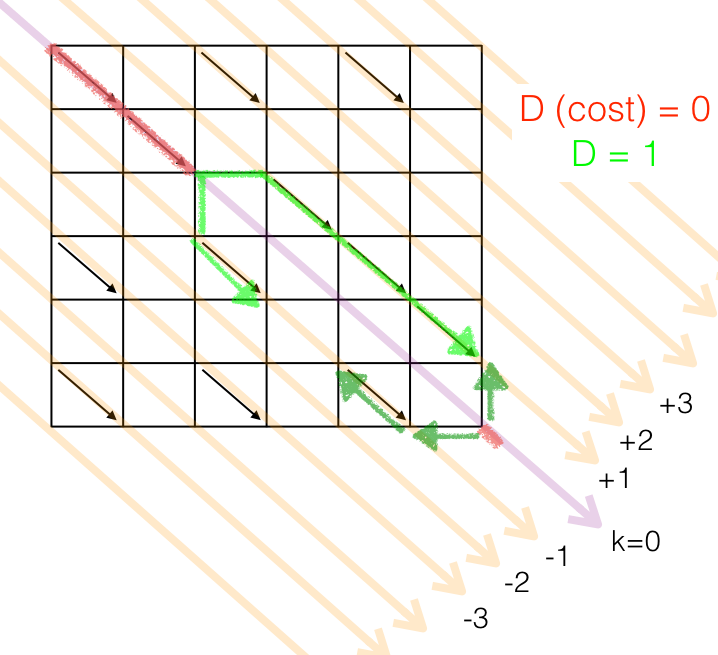
Quando dois segmentos se sobrepõem (a totalidade das implementações chama essa sobreposição de "cobra do meio"), o trecho do script de edição correspondente a essa "cobra" é anotado. Os trechos antes e depois da "cobra do meio" são recursivamente tratados pelo mesmo algoritmo Myers bidirecional.
A vantagem desse método é usar muito menos memória, porque nunca é preciso armazenar todo um caminho. O script de edição vai sendo produzido conforme a recursão avança. Isso a troco de um pequeno consumo de pilha, e o dobro de trabalho de processamento.
Um algoritmo mais antigo, que foi empregado no diff original, é o Hunt-McIlroy. Resolvi citá-lo por interesse histórico e por ser, talvez, mais fácil de entender que o algoritmo Myers. Ele gera bons resultados, mas não necessariamente o script de edição mais curto, como o Myers gera.
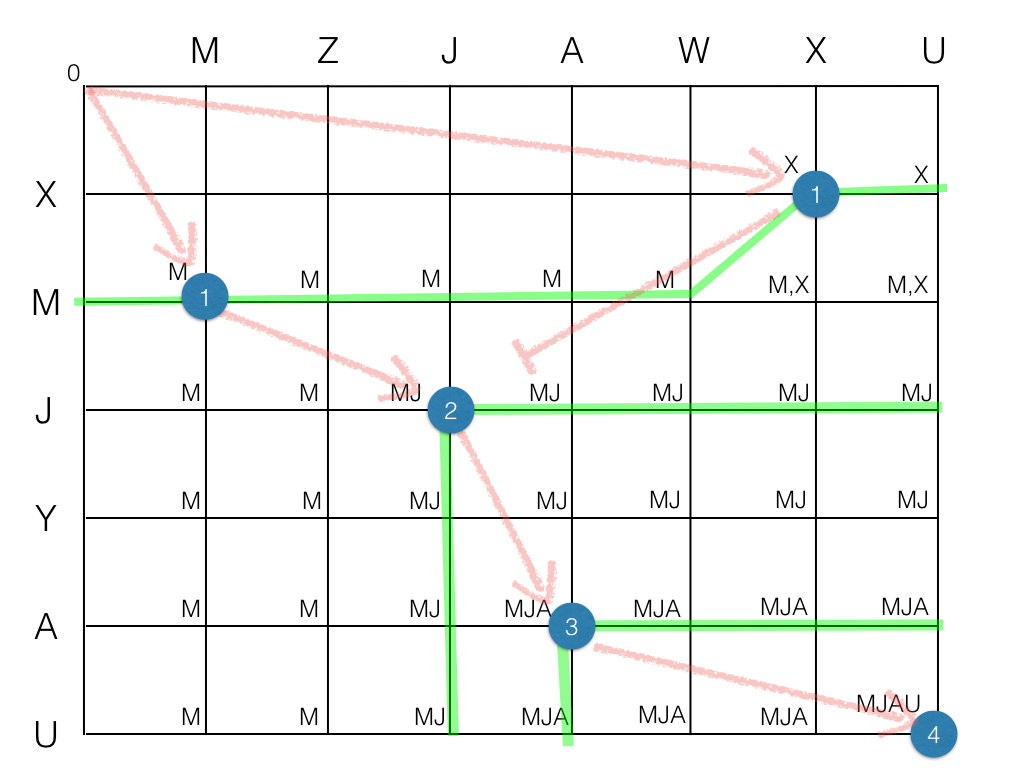
O algoritmo "clássico" para encontrar a LCS é calcular uma matrix MxN com as LCS parciais até cada ponto, e então procurar pelo caminho mais curto. A figura acima ilustra o processo, mostrando as LCS em cada ponto (M, MJ, MJA, MJAU), embora uma implementação só precise armazenar seus comprimentos. As linhas verdes mostram as "fronteiras" onde muda o comprimento das LCS parciais.
O principal problema desse algoritmo é ocupar uma área MxN de memória, o que significaria 100 milhões de números para comparação de dois arquivos de 10 mil linhas.
O algoritmo Hunt-McIlroy concentra o trabalho nos chamados "candidatos-k", que são os pontos azuis onde há elementos em comum entre as duas strings. Estes pontos são importantes porque é onde a LCS parcial muda de tamanho (só pode haver subseqüências em comum se existem elementos individuais em comum, afinal de contas).
Gerar uma matriz apenas com os candidatos-k gasta muito menos memória que uma matrix MxN, então já se obtém de plano uma grande economia de memória.
Este algoritmo é um bom exemplo de "programação dinâmica", cujo significado na literatura especializada é: formar uma tabela em memória com resultados intermediários e depois trabalhar em cima dela. Neste caso a tabela contém os candidatos-k.
A procura de um caminho que conecte candidatos-k de todos os níveis é eficiente. Uma regra crucial do algoritmo é nunca regredir, para cima nem para a esquerda. Na figura, o candidato-k do canto superior direito é um beco sem saída, pois não existe um candidato-k de nível 2 abaixo e à direita dele. É proibido ir à esquerda.
A solução encontrada pode ou não ser ótima, dependendo da estratégia empregada para unir os candidatos-k. Estratégias simples tendem a medir apenas a distância de uma "camada" para a próxima, e podem produzir resultados sub-ótimos. Por outro lado, uma solução ótima (que explore todos os caminhos possíveis) tende a usar muita memória.