 Depth of field versus sensor size
Depth of field versus sensor size
Depth of field versus sensor size
Depth of field versus sensor size
In spite of all technological advance and easy access to information nowadays, a subject of photography is still dominated by folklore and myths: depth of field.
Every photographer knows what depth of field is, but for completeness I will write once again the definition: it is the range of distances in which the scene looks sharp. Note that I said "looks sharp" instead of "is sharp". The maximum sharpness belongs to the exact focused distance, but depth of field is a tolerance range. Objects outside of this range (nearer or more distant) will be definitively out of focus in the picture.
Depth of field is influenced by several factors: focal length, lens aperture, sensor or film size, and of course the distance of the objects that one intends to shoot with sharpness.
Factors outside the control of the photographer like: lens resolution, effective sensor resolution, final enlargement of the print, print paper resolution, etc. also weigh on the depth of field. Even subjective factors like the viewer's visual acuity and the scene characteristics will have their effect, so all depth of field calculations and tables that you can find are mere estimations.
Let's begin by tackling the biggest folklore of the depth of field, that has probably driven you to this page: the relationship of depth of field with the size of the sensor.
Yes!
Consider a lens, mounted in two cameras with different sensors (e.g. full frame and APS-C). The depth of field will be, generally, shallower for the smaller sensor. Surprised?
So, if you mount a 50mm lens on a Nikon D800 (full-frame sensor), take a picture and then mount the lens on a D7100 (APS-C sensor), the depth of field will be a bit shallower in the D7100.
In spite of the depth of field markings on lenses (that suggest it is invariant for a given lens) the sensor size does influence the depth of field. Both the markings and those universal tables are all wrong for digital cameras that don't happen to be full-frame.
Depth of field is related to the size of pixels on the sensor. The megapixels of most cameras in the market are in the same order of magnitude (between 10MP and 30MP). The pixel size is approximately proportional to sensor size. Therefore, smaller sensors have smaller pixels, and their tolerance to out-of-focus images is smaller. Less tolerance, less depth of field.
Repeating: the depth of field tables found everywhere are calculated for 35mm film. They need to be adjusted even for full-frame cameras, because different cameras have different pixel sizes. This is a table made in Google Docs so you can play with different sensor sizes.
But, where does this myth come from — that depth of field wouldn't change, or would increase, as the sensor size shrinks? It has roots in other facts.
First: a given focal length means pretty different fields of view for different sensor sizes. A 50mm lens is "normal" for full-frame, but it is a "portrait lens" for APS-C. And it would be almost a telescope in a cell phone camera.
So, photographers tend to compare depth of field of lenses with the same magnification for different sensors. For example, a 50mm lens in full-frame is compared to a 35mm lens for APS-C, and to a 10mm in a compact camera. All these lenses, coupled with those sensors, offer the same field of view and the same perspective of the scene.
Second: the resolution of a whole system (sensor + lens + processing software) is always smaller than the raw sensor's resolution. More often than not, the lens has much less resolution than the sensor, and then depth of field will depend exclusively on the lens. This feeds the myth that depth of field depends only on focal length.
What happens with the depth of field in each combination of sensor + lens? That's what we are going to find out.
As almost every photographer knows, depth of field gets shallower as the focal length increases. But in which proportion?
If it were a linear proportion (2x the focal length = 0.5x depth of field), the depth of field would be more or less the same in all cameras, regardless of sensor size, since smaller sensors ask for shorter lenses, and one thing would compensate the other.
But it is not a linear relationship. Depth of field varies quadratically with the focal length.
Here we have the actual explanation for the folklore "smaller sensors have bigger depth of field". For a full-frame sensor, the "normal" lens is 50mm. For a compact camera sensor, the normal lens would be 10mm. A lens 5x shorter has 25x more depth of field; this gain is partially offset by the 5x reduction in sensor size, that makes the depth of field 5x shallower (assuming that both have the same megapixels). The bottom line (25 divided by 5) is a gain of 5x on depth of field for the compact camera.
So, for a constant field of view, the smaller sensor has deeper depth of field, because of the quadratic effect of focal length.
Because of that, TV cameras tend to use small sensors, to achieve big depth of field and be able to use large apertures. The alternative would be to use small-aperture lenses that would need much more lighting. Smaller sensors are also cheaper. Double advantage.
In still photography and cinema, the shallow depth of field is artistically valued, so larger formats are preferred. Since larger formats are exponentially more expensive (full-frame cameras are expensive already) the "cheapest" method to get very shallow depth of field is to use long lenses (large focal length), that leverage on the quadratic relationship.
If we cannot replace the camera and don't want to use long lenses, how can we make depth of field shallower? We can widen the aperture.
Depth of field is linearly proportional to f-number. The bigger the f-number, the narrower the aperture, and more depth of field we get.



Conversely, we can make depth of field shallower by using lenses with wider aperture (smaller f-number). The object of desire of every photographer is an f/1.4, f/1.2 or even f/1.0 lens.
A little problem of wide-aperture lenses is the price, that increases exponentially. An f/1.4 lens costs three times as much as an f/1.8, and a lens f/1.2 costs twice an f/1.4. Indded the f/1.2 lens will have a shallower depth of field than the f/1.8 unit, but perhaps not enough to justify the eight-fold cost.
It is noteworthy that, in terms of light admittnce, "f-number" is a quadratic measure. The f/1.0 aperture admits four times more light than f/2.0. This is because light admission depends on aperture area, but f-number is a measure of diameter, as a fraction of the focal length.
Depth of field is inversely propotional to the aperture diameter (entrance pupil). Since the f-number is exactly a measure of diameter, the relationship happens to be inversely linear.
Actually, depth of field is inversely proportional to the absolute diameter of the aperture, also called entrance pupil.
For example, a 20mm f/5.6 lens has a maximum pupil of 36mm (200 divided by 5.6). On the other hand, a 10mm f/5.6 lens has a pupil with less than 2mm. Both illuminate the sensor equally, but the second one will have a deeper depth of field.
This explains the "quadratic effect" of focal length on depth of field. Actually I lied to you: the effect of focal length on depth of field is merely linear as long as the entrance pupil is constant. For example, a 50mm f/2 lens has only twice the depth of field compared to a 100mm f/4 lens, because both have the same entrance pupil: 25mm (100 divided by 4, and 50 divided by 2).
But, in practice, nobody thinks in terms of absolute pupil. We always compare lenses with the same capability of illuminating the sensor, for example 50mm f/2 and 100mm f/2. The first will have four times the depth of field, since it has a) half the focal length; and b) entrance pupil with half the diameter.
The theoretical definition of depth of field is based on the concept of "circle of confusion". In a sharp image, every point of the scene is projected as a point on the sensor. In a fuzzy image, every point is projected as a circle, and adjacent points will smear each other, since their projected circles will overlap on the picture.
If lenses were perfect and sensors had infinite resolution, only the points perfectly in focus would look sharp. If the lens were focused at 5 meters, an object distant 5001mm would already show some loss of sharpness. Depth of field would not exist as we know it!
But, every optical system has many limitations that impair sharpness. Even the sharpest points of a scene will be projected as small circles, not as points. The sensor resolution is also limited; from the point of view of the sensor, a "point" has the size of a whole pixel.
So, up to a certain point, out-of-focus points of the image will still look sharp on the picture, since the circles of confusion are masked by the limitations of the camera+lens system.
All objective factors that influence depth of field are related to the circle of confusion:
If we define the acceptable circle of confusion as the pixel size of the sensor, or perhaps as 1.5 or 2 pixels. we finally have a truly objective definition for depth of field, right? In practice, this definition is not that useful. The theoretical depth of field would be shallower than the observed one. The printed picture would show more in-focus objects than expected.
When choosing a camera to buy (full-frame, APS-C or Four Thirds), there is the question: which is the depth of field that I get for each sensor? The rule of thumb is: crop factor multiplied by f-number.
For example: in full-frame, a 50mm f/4 lens offers a depth of field "x". In the Four Thirds system, we need a 25mm lens to have the same field of view (since the crop factor of the system is 2.0x). In order to get the same depth of field "x", we need an aperture of f/2 to balance the equation.
We can say this in the other way round: in order to get a shallow depth of field, we need f-numbers half as big in Four Thirds than full-frame, and 2/3 as big in APS-C than full-frame — always considering the same field of view.
This is a direct result from the reasonings laid out since the beginning of the article, but it doesn't hurt to demonstrate again.
The circle of confusion (CoC) is proportional to the entrance pupil, the magnification by focal length, and magnification by the crop factor (smaller sensor, bigger enlargement).
CoC ~= p . d . c
Since the entrance pupil is the focal length divided by aperture's f-number,
CoC ~= d . d . c / f
Considering a constant enlargement, and therefore a constant field of view for different crop factors (e.g. 50mm full-frame and 25mm Four Thirds have equivalent fields of view), we can simplify the proportion, since part of it is a constant:
a = constant enlargement d . c = a (constant) CoC(a) ~= d / f
We want to find the proportion between CoC and crop factor, so
d . c = a c = a / d CoC(a) ~= 1 / (c . f)
That is, given a constant field of view, CoC is inversely proportional to the crop factor and to the f-number. Since depth of field is the inverse of CoC, we can say that depth of field is directly proportional to f-number and crop factor.
Keeping the same depth of field implies keeping the product (f-number × crop factor) constant; so, if the crop factor increases, the f-number must decrease.
This reasoning shows what we have said in the beginning of the article: given a fixed focal length, increasing the crop factor will reduce, instead of increase, the depth of field. If it wasn't the case, the difference between full-frame and other formats would be even more dramatic (f/2 in Four Thirds would be equivalent to f/8 in full-frame, and not f/4 as we found).
As said before, every optical system has many limitations that decrease sharpness, increase tolerance to circles of confusion, and therefore increase the effective depth of field:
Therefore, the photographer may be seeking for a sharpness that won't be seen by anybody.
Or: if the intention was to blur part of a scene, make it very blurry indeed, to avoid the risk of it looking sharp to the eyes of the final user!
Given these uncertainties, the old empirical formulas are still employed to estimate the "acceptable circle of confusion". The most well-known is the "Zeiss formula": divide the diagonal length of the sensor (d) by 1730. The estimations d/1500 and d/1000 are also popular.
Different tables of depth of field use different estimations (note that difference between d/1000 and d/1730 is almost twofold) and most tables don't take the sensor size into account; they simply assume that smaller sensors have smaller resolution.
In my Google Docs table, I used a different estimation: width divided by 1300, which is roughly equivalent to d/1500 (d/1562, to be exact). The calculated values match the DoFMaster site, but each table or site that calculates depth of field may deliver a slightly different result.
At first, I had estimated width divided by 1500, which is nearer the "Zeiss formula"; but I did some empirical tests in my own equipment, and dividing by 1300 was a better fit. You can and should test your own equipment to check if the circle of confusion is correctly estimated.
A further development in the estimation of the circle of confusion is the infamous diffraction. Diffraction reduces sharpness for narrow apertures. Diffraction also "swells" the depth of field, reducing the general sharpness and making areas slightly out-of-focus look as good as the in-focus areas.
If you look carefully at Figure 2 you may see that the right (in-focus) coupon, shot at f/5.6, is a bit sharper than the right coupon at Figure 3 that was shot at f/16.
It is a small difference, but if the circle of confusion were calculated with basis on the second image, it would be something like d/1000, which underestimates the maximum sharpness of our system.
If we consider that 1 circle of confusion = 1 pixel, the estimation that we made for the circle of confusion (width divided by 1300) is equivalent to 1.2MP (1300x866). Quite a disillusion! In a camera that sells as 24MP...
But this estimation is too pessimistic. First off, circles of confusion could be arranged like a honeycomb instead of a grid. The hexagonal packing of circles is 15% denser than square packing.
A more well-grounded argument can be found at this article that talks about diffraction circles but the general problem is similar. In order to define equivalence between the size of the circle of confusion and the resolution, we must choose first the acceptable contrast level between two adjacent pixels, also known as MTF.
The animation below shows circles of confusion of different sizes, and how they are resolved into pixels (squares) by a sensor:
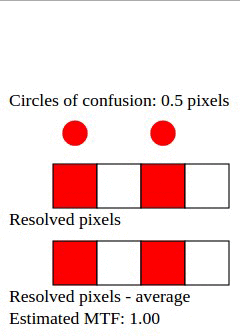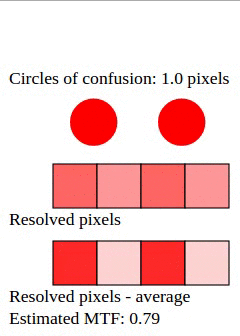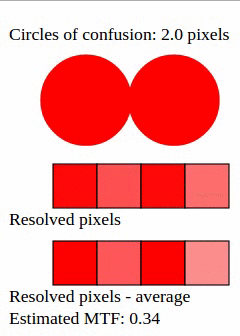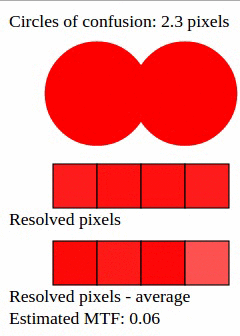
Suppose that a given image has two distinct points, separated by a space equivalent to 2 pixels. It could be two narrow lines, or two stars in the sky, etc. Each point is projected as a circle of confusion on the sensor.
Depending on the size of the circle of confusion, and where it falls onto, each circle will illuminate the one pixel that it should, and also some adjacent pixels that it shouldn't. For perfect contrast, each circle should illuminate just one pixel. When the circle of confusion (CoC) is around half a pixel in diameter, they are resolved with 100% contrast in most cases.
The worst case is when circles fall exactly between two pixels. The pixels "resolve" the two points into a continuous blur, and they cannot be distinguished at all in the final image.
Taking an average of all possible cases, the MTF for circles of confusion with size 0.5 pixel is around 85%. (My animation estimates MTF at 87% for this case, but it is purely empirical; it is more like a first approximation.)
As the diameter of the circle of confusion increases, the likelihood of "smearing" increases as well. The MTF for 1-pixel circles is around 80%; for 1.5-pixel circles, MTF is around 50%; for 2-pixel circles, MTF is 20%. If circles grow even bigger, MTF tends to zero.
In photography, the definition of "sharp" is MTF of 50% or better. Accordingly to technical articles and to our animation, this MTF is achieved when the circle of confusion has a diameter of 1.5 pixel.
Now let's see a practical example:

In the Figure 5 above, the number 50 seems to hover above the tape, because it is so sharp. The effect is more visible in the original picture, without the severe crop that we did above. The color contrast also helps.
Now, a huge magnification of the red 5, that shows every individual pixel:

In the Figure 6 above, you can search as long as you want, but you will not find two adjacent pixels with a difference of 100% (that would mean an MTF of 100%). Between pure red and pure yellow, there is always at least one intermediate (orange) pixel. This is 50% MTF.
We can also see that black lines of the tape measure are so thin, that 50% MTF was not enough to deliver truly black pixels; they are a shade of murky brown. But in the original picture, the lines do look black. Empirically, we can see that 50% MTF is visually sharp.
Therefore, we will update our resolution estimation, considering that each circle of confusion is equivalent to 1.5 pixels. This translates to 2.75 megapixels, much more realistic. We can round this up to 3MP.
No!
In spite of the estimated resolution (3MP) being eight times lower than the camera's resolution (24MP), a high-resolution sensor is not useless. This comparison is between apples and oranges — one cannot expect to get the final picture with the same raw resolution of the sensor.
The first reason was already mentioned: the demosaicing process takes away some resolution. The 24MP are reduced to something like 12MP or 16MP right off the bat. The difference to 3MP has already shrunk to 4x or 5x.
The second reason is, defining resolution as megapixels is a bit deceiving. It would be more correct to count pixels in just one dimension (width or height). An image with 4x more megapixels has circles of confusion only 2x bigger. Seeing this way, a 12MP image is only twice as good as 3MP.
Finally, the most important technical reason: the circles of confusion created by every optical imperfection (out of focus, lens, sensor, diffraction, demosaicing, etc.) are compounded as an RMS sum.
For example, consider a lens and a sensor with the same resolution. Lens diffaction creates a "point" of 10µm with sharpest focus, and the sensor pixel size is also 10µm. The common sense suggests the CoC of the system is simply the largest CoC found throughout the system (10µm), but the effective CoC is actually 14µm. At least it is not as bad as a linear sum (that would be 20µm).
Taking this into account, it is good to have a sensor with the maximum resolution possible. A sensor with 5µm pixels and a lens with 10µm of resolution has a system CoC of 11µm. In this case, the system resolution is clearly limited by the weakest component (the lens), and it can be greatly improved just by replacing the lens.
Of course, higher-resolution sensors (with pixels that are too small) bring other problems, e.g. less sensitivity to light and more noise, but this does not mean that smaller resolutions are inherently better, either.