 Detecção e correção de erros
Detecção e correção de erros
Detecção e correção de erros
Detecção e correção de erros
Detecção e correção de erros (EDC) são algoritmos vitais no mundo atual. Absolutamente todos os meios de comunicação atuais dependem de EDC para funcionar, e a informática depende totalmente da detecção de erros para se confiável. Imagine se uma transferência bancária tivesse uma chance palpável de ser corrompida no caminho?
De fato um erro não-detectado é um problema muito maior quando se trata de dinheiro. Em outras áreas, como vídeo ou áudio, erros podem ser toleráveis. Por isso mesmo, uma excelente metáfora para algoritmos de EDC vem justamente da área bancária: o dígito verificador.
Todo mundo conhece o tal do dígito verificador, presente em números de conta de banco, boletos bancários, cheques, no CPF, no CNPJ e em muitos outros códigos. Por exemplo, este número de conta:
1532-6
O número principal ou "real" da conta é 1532, o dígito 6 é normalmente o resultado de uma operação matemática em cima do número principal.
Todo mundo conhece o dígito verificador (DV) e às vezes ele chateia nossa vida. Às vezes o banco pede o DV da agência, às vezes não. E quando pede, não lembramos dele e não conseguimos fazer a operação bancária desejada.
Mas nem todo mundo sabe para que ele serve: pegar erros de digitação. O valor do DV depende dos demais dígitos; se algo é digitado errado, o DV calculado será diferente e o erro é detectado.
Por exemplo, se usarmos o algoritmo "módulo 11", o DV da conta bancária 1532-6 é calculado da seguinte forma:
1 5 3 2 x 5 4 3 2 ------------------- 5 + 20 + 9 + 4 = 38 38 / 11 = 3, resto da divisão = 5 11 - 5 = 6 dígito verificador = 6
Se em vez de 1532-6 o digitador entrar 1523-6 (sendo que o respectivo DV desta conta seria 1523-7) o sistema detecta o erro e rejeita a conta. Mas note que o sistema não sabe qual dígito está errado. Nem sabe se a conta certa era 1532 ou 1523. Este algoritmo apenas detecta erros, não corrige.
A princípio, desenvolver um algoritmo para DV parece muito fácil. Em vez de usar o "módulo 11", poderíamos simplesmente somar os dígitos, certo? Errado... Uma simples soma não pegaria o erro do exemplo acima, pois 1+5+3+2 é igual a 1+5+2+3.
O algoritmo ideal para dígito verificador cumpre diversas exigências:
Nenhum algoritmo cumpre completamente as exigências acima, mas o "módulo 11" chega bastante perto.
Existem algoritmos que levam em conta o layout do teclado e os erros mais comuns que os digitadores cometem na prática, porém são baseados em tabelas, enquanto o módulo 11 é um cálculo muito simples. Por isso é de longe o mais utilizado na prática.
No caso de códigos como CPF e CNPJ, há dois dígitos verificadores, então idealmente eles pegam todos os erros de até dois dígitos, e 99% de erros maiores.
A propósito, CPF e CNPJ usam uma versão levemente modificada do "módulo 11" para obter seus DVs. Além dos DVs, todos os números do CPF e CNPJ guardam relação matemática entre si, de modo que (teoricamente) apenas o governo seja capaz de emitir CPFs válidos. Um CPF como 11.111.111-80 tem DVs válidos mas o governo ainda detecta que ele é falso. (Geração de códigos resistentes à fraude já é assunto de criptografia, fora do nosso escopo.)
O módulo 11 consegue detectar erros de inversão porque ele multiplica cada dígito por um "peso" diferente (2, 3, 4, até 7 e recomeçando em 2), e pesos adjacentes são relativamente primos, de modo que toda inversão simples resulta num DV diferente.
Observe que a conta bancária "pura" tem 4 dígitos, o que significa 10.000 combinações possíveis. Já a conta bancária com DV tem 5 dígitos, ou 100.000 combinações. Porém, das 100 mil, 90 mil são inválidas. É assim que um DV consegue pegar 90% de qualquer erro de digitação.
Porém, o módulo 11 consegue pegar todos os erros simples, não apenas 90% deles. Esta é a propriedade mais difícil de garantir, e é uma das mais importantes a se entender.
Para que um DV pegue todos os erros de um dígito, precisamos garantir que cada conta bancária seja diferente da outra em pelo menos dois dígitos. Ou seja, a distância de Hamming entre cada conta válida seja igual ou maior que 2.
Números que sejam diferentes em apenas um dígito são considerados "vizinhos"; a distância de Hamming (DH) entre eles é igual a um. Exemplo:
1523-6 .. 1523-7 válido inválido
Entre números que sejam diferentes em mais de um dígito, podemos imaginar que existam "caminhos" que levem de um até o outro, passando por diferentes vizinhos, trocando um dígito de cada vez:
1532-6 .. 1532-7 .. 1522-7 .. 1523-7 1532-6 .. 1522-6 .. 1523-6 .. 1523-7 válido inválidos válido
Como o exemplo acima tentou mostrar, existe mais de um caminho possível entre dois números. O que importa é "distância", que no exemplo acima é DH=3. Note ainda que, como os números inicial e final são contas válidas, os números intermediários são inválidos.
Duas contas diferentes já têm pelo menos um dígito diferente no próprio número da conta (e.g. 1523 e 1524). Um segundo dígito diferenciado tem de ser fornecido pelo dígito verificador.
O algoritmo módulo 11 praticamente garante que, se duas contas diferem em apenas um dígito, o DV delas também será diferente.
Isto nos dá uma distância de Hamming DH=2, no mínimo, que nos permite detectar qualquer erro simples. Digitar um número errado resulta numa conta com DH=1 a partir da conta valida — o que é claramente inválido já que todas as contas válidas têm DH=2 umas das outras.
O módulo 11 ainda fornece uma garantia adicional: se dois números são diferentes em 2 dígitos apenas por conta de uma inversão, o dígito verificador será necessariamente diferente.
Por exemplo, as contas 1523 e 1532 já têm DH=2, mas o módulo 11 garante que neste caso o DV também será diferente, o que nos garante DH=3 e nos permite pegar 100% dos erros de inversão — que a rigor são erros de dois dígitos, cuja taxa "normal" de deteção é 90%.
Esta proteção contra inversões é importante para o caso de uso do módulo 11 (digitação) porém ele cobra seu preço noutro lugar: a proteção contra erros "ordinários" de dois dígitos ou mais são detectados com um pouco menos de 90% de sucesso.
Na teoria, um dígito verificador pegaria 90% dos erros. Porém o módulo-11 gera onze códigos possíveis (0 a 10) enquanto o DV só pode assumir dez valores possíveis (0 a 9). A solução usual — truncar 10 para 0 ou 1 — rouba um pouco do poder de detecção.
Em alguns bancos, como o Banco do Brasil, o dígito verificador pode assumir o valor "X", também chamado de "prejudicado". Neste caso o DV pode assumir onze valores distintos (0 a 9, ou X) e a eficiência do módulo 11 é mantida em 90%.
Com um algoritmo de "dígito verificador" apropriado, podemos não só detectar erros, mas também corrigi-los, sem exigir redigitação.
À primeira vista isto soa como bruxaria porém é uma conseqüência natural da distância de Hamming.
Considere o seguinte "caminho" hipotético entre dois números válidos, com um DV triplo (já vou explicar por que tem de ser triplo):
1523-356 .. 1524-356 .. 5524-356 .. 5524-396 .. 5524-390 válido inválido inválido inválido válido
Usando um DV triplo, podemos garantir uma distância de Hamming DH>=4 entre dois números válidos. Para corrigir um número errado, simplesmente adota-se o número válido mais "próximo".
Por exemplo, se recebemos o número 1524-356 (inválido), adotamos 1523-356 em seu lugar, já que são "vizinhos". Se recebêssemos 5524-396, adotaríamos 5524-390 que está mais próximo.
No caso do número inválido 5524-356, não poderíamos corrigir o erro, já que ele está igualmente distante de 1523-356 e 5524-390. Temos de nos contentar em detectar o erro.
Esta é uma característica de todo código de correção de erros: acima de uma certa contagem de erros (aproximadamente metade da distância de Hamming), o algoritmo não mais corrige, apenas detecta. A fórmula é a seguinte:
h = distância de Hamming d = h-1 c = (h-1)/2 Exemplo: h = 4 d = 4-1 = 3 (detecta 100% dos erros de até três dígitos) c = (4-1)/2 = 3/2 = 1 (corrige 100% dos erros de até um dígito)
É importante mencionar que a "força" de detecção e correção de erros independe do comprimento do número. Podemos utilizar números de 400 dígitos em vez de 4, que nada se altera. Só importa a distância de Hamming.
Esta é a teoria, mas achar um algoritmo que produza um código de correção de erros não é simples. O grande desafio é conseguir determinar, dado um valor errado, qual é o valor válido mais "próximo", a fim de executar a correção.
Usamos números decimais como exemplo acima, e existem algoritmos de correção para números decimais, porém não são ideais. A correção é mais bem implementada utilizando-se números binários.
A bem da verdade, não há muitos casos de uso para correção de erros de números decimais. (No caso da digitação, basta detectar os erros e mandar o digitador repetir.) A correção de erros é mais útil em outros casos de uso:
Mas nestes casos de uso a utilização de números binários é mais conveniente.
Mesmo substituindo os números decimais por binários, os mecanismos não mudam. A distância de Hamming continua sendo o "ingrediente" básico para obtermos detecção e correção de erros.
O que muda é o "poder de fogo" da detecção de erros acima da capacidade do código. Por exemplo, o dígito verificador decimal pode detectar até 90% dos erros de dois dígitos ou mais. Já o seu equivalente binário, o bit de paridade, detecta apenas 50% dos erros de dois bits ou mais.
Isto acontece simplesmente porque um dígito decimal tem muito mais valores distintos que um dígito binário (bit). No caso de um DV duplo como o do CPF, 99% dos erros são pegos, enquanto um código de 2 bits pega apenas 75% dos erros. A taxa de detecção é dada por:
n = número de dígitos verificadores ou bits do código p = probabilidade de pegar erros de mais de "n" dígitos b = base numérica (binário=2, decimal=10) p = (b^n-1)/b^n Exemplo: 2 dígitos decimais p = (10^2-1)/10^2 = (100-1)/100 = 99/100 = 99% Exemplo: 16 dígitos binários (CRC-16) p = (2^16-1)/(2^16) = 65535/65536 = 99,9984%
Códigos com poucos bits são relativamente fracos, porém adicionar 16, 32 ou mesmo 128 bits a uma mensagem custa muito pouco, e um código com 16 bits já apresenta uma força bastante respeitável, conforme o exemplo acima.
Resta agora encontrarmos algoritmos de detecção e correção de erros que sejam adequados a números binários.
Na pré-história da informática, a detecção de erros mais "avançada" era o bit de paridade. Ele ainda está presente em comunicações seriais (RS-232) e em alguns tipos de memória RAM. A grande maioria das tecnologias já usa tecnologia mais avançada, como CRC ou Reed-Solomon, que veremos mais à frente.
A idéia do bit de paridade é fazer com que cada fragmento de mensagem (cada byte, por exemplo) tenha um número par ou ímpar de bits "1" — ou seja, há dois tipos de paridade.
Supondo a paridade "par", se houver um número ímpar de bits no byte, o bit de paridade será "1" para compensar. Do contrário, o bit de paridade será "0".
A implementação da paridade em hardware é muito simples, basta "somar" todos os bits com XOR (e inverter o resultado no caso de desejarmos paridade ímpar).
É quase óbvio que a paridade detecta 100% dos erros de apenas um bit, e 50% dos erros maiores. É portanto um esquema relativamente fraco, e muito fraco se considerarmos a redundância que ele gera (8 bits viram 9, ou seja, +12,5%). Paridade só tem valor como detector de erros quando a ocorrência de erros é quase zero, uma anomalia.
Curiosamente, a paridade é um caso-limite de um algoritmo muito mais forte, o CRC. Um código CRC de 1 bit corresponde à paridade.
Como vimos, o módulo 11 é um algoritmo quase perfeito para detecção de erros em números decimais. Precisamos de algo parecido para números binários.
Parecido porém diferente, porque o resto de uma divisão binária só pode ser 0 ou 1, então qualquer algoritmo baseado em resto de divisão geraria códigos muito pobres.
O algoritmo consagrado CRC emprega resto de divisão, porém divide polinômios, não números. O resto de uma divisão polinomial pode ser tão variado quanto se queira, basta escolher bem o divisor.
Do ponto de vista do CRC, um número binário é um polinômio:
1000101 = x^6 + x^2 + 1
Além de tratar binários como polinômios, o CRC considera que todas as operações aritméticas ocorrem num campo GF(2), ou seja, nela só existem 0 e 1:
GF(2) 1 + 1 = 0 0 - 1 = 1 2n = 4n = 6n = 8n = ... = 0 n = 1n = 3n = 5n = 7n = ...
Observe acima que, em qualquer operação GF(2), um resultado par vira 0, e um resultado ímpar vira 1.
O mais curioso é que implementar o CRC na prática é muito fácil, tanto em software quanto em hardware. Principalmente em hardware, basta umas poucas portas XOR. Os polinômios são um artifício que permite a demonstração matemática rigorosa, que prova que o CRC cumpre seu papel de detectar erros.
Todo o poder de fogo do código CRC depende do divisor escolhido, também chamado de "polinômio gerador". O requisito básico é o polinômio possuir os termos x^n e 1, onde "n" é o número de bits verificadores a ser adicionados à mensagem. Isto significa que e.g. um CRC de 16 bits pede um polinômio de 17 bits, com os bits mais alto e mais baixo iguais a 1.
Esperamos que um CRC de 16 bits detecte 100% dos erros de até 16 bits. Porém, a concretização disto depende de escolher o polinômio gerador correto. Para um CRC de 16 bits, há 2^15=32768 candidatos e a maioria não presta — vai detectar menos erros do que o teoricamente previsto.
Na prática, para evitar uma má escolha, as implementações usam polinômios já consagrados. Por exemplo o polinômio 0x11021 é comumente usado para produzir CRCs de 16 bits. Seu "apelido" é CRC-16 CCITT, pois foi selecionado como padrão pela entidade CCITT (hoje ITU-T).
Como o bit mais alto do polinômio gerador é sempre 1, ele é normalmente ocultado na literatura. Assim, o CRC-16 consta simplesmente como 0x1021 na maioria das publicações; o acréscimo de 0x10000 fica subentendido.
O CRC mais simples possível é, naturalmente, de 1 bit, e seu polinômio gerador só pode ser (x + 1). Ele produz o mesmo resultado do bit de paridade — que sempre detecta erros de até 1 bit.
Para ilustrar de forma bem simples como o CRC consegue detectar erros, vou usar números decimais e divisão "normal", para depois partir para um exemplo mais realista.
Mensagem M = 123456789 Polinômio gerador G = 271
Se o polinômio gerador tem 3 dígitos, ele vai entregar um código de três "dígitos verificadores". Eu adiciono zeros à mensagem para acomodar os dígitos, calculo o CRC e diminuo seu valor da mensagem:
M' = 123456789000 CRC = resto de M' / G CRC = 123456789000 % 271 = 3 M'' = M' - CRC = 123456789000 - 3 M'' = 123456788997
A mensagem M'' é transmitida, e no lado receptor ela é dividida pelo mesmo polinômio gerador G. Se a mensagem estiver ok, o resto tem de ser zero.
Para recuperar a mensagem original, devemos remover os três últimos dígitos, que contém o valor "invertido" do CRC. E se eles eram diferentes de zero, temos de somar 1 à mensagem para compensar a subtração feita durante a transmissão:
123456788997 % 271 = 0 (ok) 123456788 + 1 123456789
Este é o princípio básico do CRC. Ainda que seja um exemplo "falso" por não usar polinômios, já dá pra entender por que a escolha de G é crucial. Um divisor "redondo" como 300 produziria CRCs sempre iguais a zero, que não detectam erro algum. Um divisor par nunca produziria um resto ímpar, o que deixa de aproveitar metade dos valores possíveis para o CRC. E assim por diante.
No caso do exemplo acima, o polinômio gerador ideal é um número primo de três dígitos. No CRC "de verdade" é um polinômio "ímpar" (terminando em ... + 1) e que não seja muito redutível (ou seja, não seja resultado da multiplicação de vários polinômios mais simples). Uma regrinha para obter candidatos iniciais a G é multiplicar um polinômio irredutível por (x + 1).
Agora vamos fazer um CRC de verdade, com números binários e polinômios. Só vou me conceder a licença de usar uma mensagem curta e um CRC de apenas 3 bits para facilitar minha vida.
mensagem M = 10011111 gerador G = 1001 adiciona três zeros M' = 10011111 000 Convertendo para polinômios M' = x^10 + x^7 + x^6 + x^5 + x^4 + x^3 G = x^3 + 1
Agora vamos fazer a divisão de M' por G usando uma calculadora online que divide polinômios.
resto de M'/G = - x^2 - x em GP(2) = x^2 + x CRC binário = 110 M'' = M' - CRC = 10011111 110
M'' é transmitido, no lado da recepção o valor é novamente dividido por G:
M'' = 10011111 110 M'' = x^10 + x^7 + x^6 + x^5 + x^4 + x^3 + x^2 + x M''/G = x^7 + x^3 + x^2 + x resto = 0 M = M'' / 8 = 10011111
O resto da divisão (polinominal) é igual a zero, assim sabemos que M'' foi transmitido sem erros. Vamos supor que um bit de M'' foi modificado:
M'' = 10011101 110 M'' = x^10 + x^7 + x^6 + x^5 + x^3 + x^2 + x resto de M''/G = x
A presença do resto indica que M'' não está ok.
O fato da aritmética ser GP(2) permite simplificar alguns polinômios. Quando um termo é multiplicado por 2 ou outro número par, ele some. Sinais negativos podem ser convertidos para positivos.
Como em particular a operação de subtração é equivalente à operação booleana XOR neste contexto, toda a divisão polinomial pode ser implementada usando apenas XOR:
M' = 10011111000
G = 1001
10011111000 / 1001
-1001 .
---- .
0* se o bit mais à esquerda (MSB) é zero,
01* apenas baixa o próximo bit do dividendo
011* .
0111* .
1111 bit MSB é um, torna a subtrair
-1001 .
---- .
0110* .
1100 .
-1001 .
---- .
0101*.
1010.
-1001.
----
0011*
0110 não há mais bits no divisor
0110 = resto = x^2 + x + 0
Em hardware, esta operação é facilmente implementada com um registrador de deslocamento, com tamanho equivalente ao CRC que se deseja calcular (CRC-16 pede um registrador de 16 bits), e portas XOR nas posições em que o "polinômio gerador" possui o valor 1.
Uma ilustração tirada deste artigo da Wikipedia ilustra como um registrador de deslocamento "mastiga" uma mensagem:
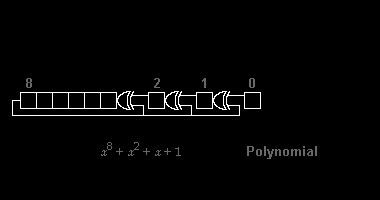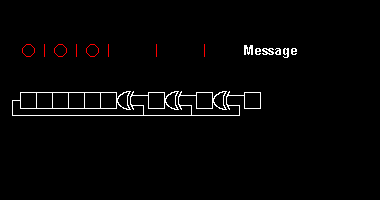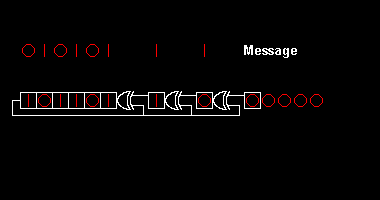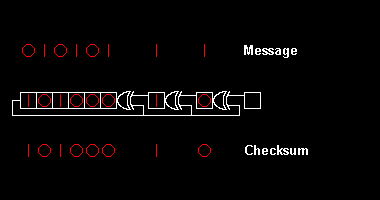
O CRC funciona segundo os mesmos princípios do humilde dígito verificador. Por exemplo, o CRC-16 adiciona 16 bits de redundância a uma mensagem. Se o polinômio gerador for bom, uma mensagem válida (adicionada do CRC) será diferente de qualquer outra mensagem válida em, no mínimo, 17 bits.
Infelizmente o CRC permite apenas detectar erros. Não é possível usá-lo para corrigir erros, pois não é possível determinar facilmente qual a mensagem válida que está mais "próxima" de uma eventual mensagem corrompida.
Na verdade, existem alguns esquemas que permitem corrigir erros de 1 bit, apenas com CRC, mas são mais objeto de pesquisa e curiosidade. Um código de 16 bits deveria ser capaz de corrigir até 7 bits errados, não apenas 1.
A busca por códigos que permitam a correção de erros têm sido objeto de pesquisa intensa desde os anos 40 e os códigos em uso atual foram em sua maioria inventados nos anos 50 e 60: código de Hamming, código Reed-Salomon, BCH, etc.
O código Reed-Solomon é particularmente popular, sendo utilizado por exemplo em CDs e DVDs, onde existe a certeza que haverá erros na mensagem, devido à sujeiras ou riscos na mídia ótica.
Um código muito simples faz uso de bits de paridade "cruzados", e é capaz de corrigir quaisquer erros de 1 bit. Exemplo com uma mensagem de 16 bits, dispostos como um quadrado 4x4:
mensagem | paridade vertical
0 1 1 0 | 0
1 0 0 0 | 1
0 0 0 0 | 0
1 1 0 1 | 1
------------+
0 0 1 1
paridade horizontal
A paridade cruzada pode corrigir qualquer erro de um bit, pois os erros de paridade dão as coordenadas do bit errado:
0 1 1 0 | 0
1 0 0 0 | 1
0 0 1! 0 | 0 <-- paridade errada
1 1 0 1 | 1
------------+
0 0 1 1
^
paridade errada
Se a paridade indicar erro em apenas uma dimensão, a corrupção ocorreu no próprio bit de paridade, não na mensagem:
0 1 1 0 | 0
1 0 0 0 | 1
0 0 0 0 | 0
1 1 0 1 | 1
------------+
0 0 0! 1
^
paridade errada
Infelizmente, este código tão simples não pode resolver erros de dois bits ou mais, pois a posição dos erros torna-se ambígua:
0 1 1 0 | 0
1 A B 0 | 1 <-- paridade errada
0 B A 0 | 0 <-- paridade errada
1 1 0 1 | 1
------------+
0 0 1 1
^ ^
paridades erradas
No exemplo acima, sabemos que estão errados os bits A ou os bits B.
O código de Hamming tem semelhanças com o código hipotético que desenvolvemos na seção anterior. Ele baseia-se em paridades cruzadas, pode corrigir qualquer erro de 1 bit e detectar qualquer erro de até 2 bits.
O código foi inventado pelo matemático Richard Hamming, que também criou o conceito de "distância de Hamming" mencionado lá em cima.
Foi o primeiro código de correção de erros utilizado na prática. Não é muito eficiente (corrige poucos erros pela redundância que gera) mas é fácil de entender e muito rápido quando implementado em hardware.
Ele ainda é utilizado quando esperam-se erros de 1 bit, em pequeno número, e o circuito de detecção e correção de erros tenha de ser extremamente rápido. Por exemplo: memórias RAM com ECC.
O código de Hamming fica mais eficiente conforme cresce o tamanho da mensagem: 3 paridades para até 4 bits de mensagem, 4 paridades para até 11 bits, 6 paridades para até 57 bits e assim por diante. O esquema abaixo é para uma mensagem de 8 bits:
Posição do bit 1 2 3 4 5 6 7 8 9 10 11 12 Bits p1 p2 m0 p3 m1 m2 m3 p4 m4 m5 m6 m7 ---------------------------------------------------- Paridade 1 (p1) x x x x x x Paridade 2 (p2) x x x x x x Paridade 3 (p3) x x x x x Paridade 4 (p4) x x x x x
Um aspecto-chave: os bits de paridade (p1..p4) estão misturados com os bits da mensagem original (m0..m7). Isto permite aos bits de paridade protegerem a si mesmos. Eles são inseridos nas posições que são potências de 2 (1, 2, 4, 8) assumindo que a contagem das posições começa em 1.
Outro aspecto: o mapa de cálculo de paridades é uma seqüência binária crescente. Por exemplo, o bit da posição 5 (m1) influencia as paridades p1 e p3, e "101" é 5 em binário. Esta propriedade é utilizada diretamente para corrigir um erro. Se a mensagem recebida apresenta as paridades p1 e p3 erradas, provavelmente é porque o bit 5 está invertido, e a mensagem (bruta) é consertada invertendo-se o bit 5.
Pelo menos duas paridades precisam estar erradas para que um bit da mensagem original esteja errado. Se apenas uma paridade estiver errada, isto significa que é a propria paridade que foi corrompida, não a mensagem original.
Exemplo de codificação de mensagem com paridade par:
Mensagem: 01101101 (109 decimal) Paridades/Bits p1 p2 0 p3 1 1 0 p4 1 1 0 1 ---------------------------------------------------- p1 =0 0 1 0 1 0 p2 =0 0 1 0 1 0 p3 =1 1 1 0 1 p4 =1 1 1 0 1 mensagem codificada: 000111011101
Agora vamos supor que a mensagem foi corrompida:
Mensagem codificada recebida: 000101011101 Paridades/Bits p1 p2 0 p3 0 1 0 p4 1 1 0 1 ---------------------------------------------------- p1 ERRADA 0 0 0 0 1 0 p2 ok 0 0 1 0 1 0 p3 ERRADA 1 0 1 0 1 p4 ok 1 1 1 0 1 Invertendo-se o quinto bit (segundo bit da mensagem original), as paridades ficam todas ok.
Outro caso, desta vez um bit de paridade foi corrompido:
Mensagem codificada recebida: 010111011101 Paridades/Bits p1 p2 0 p3 0 1 0 p4 1 1 0 1 ---------------------------------------------------- p1 ok 0 0 1 0 1 0 p2 ERRADA 1 0 1 0 1 0 p3 ok 1 1 1 0 1 p4 ok 1 1 1 0 1 Invertendo-se o terceiro bit (a própria paridade p2), as paridades ficam todas ok.
O Reed-Solomon é um código de correção de erros não-binário, ou seja, ele considera grupos de bits, e não bits individuais, como os "dígitos" (chamados de símbolos) da mensagem.
Podem ser, por exemplo, grupos de 8 bits, ou seja, bytes. Neste caso haveria 256 símbolos diferentes. Para que a correção de erros funcione, o comprimento total da mensagem tem de ser menor ou igual à varidade de símbolos — no exemplo, 256 bytes ou menos. Ou seja, o tamanho do símbolo deve ser escolhido de acordo com o tamanho da mensagem.
A geração do código Reed-Solomon é bastante semelhante ao CRC: a mensagem original M é considerada como se fosse um polinômio. Ela é deslocada e dividida pelo polinômio gerador G. O resto desta divisão é o código:
m = bits por símbolo k = comprimento do código M' = M x 2^k = M >> k C = M' % G M'' = M' - C operações aritméticas executadas num campo GF(2^m) 8 bits por símbolo = GF(256)
A maior diferença que os coeficientes do polinômio não são simples bits como no CRC: são os valores dos símbolos. Se forem 8 bits por símbolo, o coeficiente pode ir de 0 a 255.
O polinômio gerador G não é escolhido "por acaso" como no CRC; ele deve ter um número de raízes relacionado ao tamanho do símbolo e o comprimento do código de erros. Se o símbolo é de 8 bits e queremos adicionar usar um código de erro de 32 bits (4 símbolos), o polinômio gerador deve ter 4 raízes.
A fase de detecção de erro Reed-Solomon é novamente análoga ao CRC. Uma divisão polinominal de M'' por G com resto zero indica ausência de erros.
No caso de haver resto, ele é utilizado para achar e corrigir os erros. Esta parte do Reed-Solomon é bastante complicada. Este artigo descreve o processo de forma bastante didática (embora não torne o assunto fácil). Farei uma breve explanação aqui.
Se M'' não possui erros, o resto da divisão por G é zero. Isto significa que M'' é na verdade um múltiplo de G, e sendo assim, M'' tem as mesmas raízes de G — lembrando que G é construído de modo a possuir símbolos como raízes. Portanto, as raízes de M'' também são símbolos.
Se a mensagem recebida possui erros, ela pode ser definida como a "soma" da mensagem correta com um erro E:
M''' = M'' + E
M'' % G = 0
M''' % G = S
S = "Síndrome" de alguma forma relacionada ao erro E
E = a1.x^b1 + a2.x^b2 + ...
a1, a2, ... = desvios dos coeficientes
dos símbolos errados
b1, b2, ... = posições dos símbolos errados
M'' = M''' - E
Se descobrirmos qual é o polinômio E, podemos subtraí-lo da mensagem errada, corrigindo os erros. Para achar E, temos de achar as incógnitas a1, a2, a3... e b1, b2, b3...
Não sabemos (ainda) o valor de E, mas temos S, a "sindrome", que é o resto da divisão de M''' por G. Mas S e E são relacionados; o erro é um múltiplo da síndrome. E calcular S(x) ou E(x) com as mesmas raízes de G resulta nos mesmos valores:
M'' % G = 0 M''' = M'' + E M''' % G = S (M'' + E) % G = S M'' % G + E % G = S E % G = S Se x = raiz de G, E(x) = S(x)
Graças a esta igualdade, podemos montar um sistema de equações com as raízes de G, de modo a resolver as incógnitas, que são os coeficientes de E.
Note que, se temos 2 erros, o polinômio E possui 4 incógnitas (o dobro) e para achar 4 incógnitas precisamos de um sistema de 4 equações. Portanto, para corrigir até 2 erros, o polinômio gerador G tem de ter 4 raízes distintas. Esta é a razão matemática por que o código corrige menos erros do que pode detectar (um código de 16 bits detecta quaisquer erros de até 16 bits, mas só pode corrigir até 8).
Em alguns casos, o hardware "sabe" onde estão os símbolos errados. Neste caso, algumas incógnitas "b" não são mais incógnitas, e o código Reed-Solomon pode corrigir mais erros que a previsão inicial.
O trabalho original de Reed-Solomon só especificou este método sem esclarecer como ele poderia ser implementado de forma eficiente. Isto foi inventado um pouco mais tarde.
Correção de erro foi inventada para evitar perda acidental de informações. Mas ela pode ser usada de forma "maquiavélica", para extrair o máximo possível da capacidade teórica de um canal de comunicação.
A estratégia é mais ou menos a seguinte: suponha um canal que transmita 10 bits por segundo (10bps) sem erro, ou 20bps com 10% de erro. Se eu não disponho de nenhuma ferramenta de correção de erros, tenho de usar a velocidade mais lenta.
Mas, se eu disponho de correção de erros, posso transmitir a 20bps usando um código com 12,5% de redundância (100 bits de mensagem útil viram 125 a trasmitir). Com isto eu garanto que eventuais erros serão (quase) sempre corrigidos sem necessidade de retransmissão, e consigo transmitir dados à taxa de 16bps (20bps menos os bits adicionados pelo código de correção). Um ganho de 60%.
Hoje em dia, todos os meios de comunicação fazem uso desta estratégia para obter o máximo de cada canal de transmissão, seja WiFi, celular, cabos metálicos ou fibra ótica.
O código Reed-Solomon, bem como o CRC e outros códigos populares, são "códigos de bloco", ou seja, você pega a mesagem original e adiciona um sufixo, tal qual se faz com um dígito verificador.
Existe outra classe de códigos, denominados "convolucionais", em que a mensagem realmente transmitida "no fio" é:
Naturalmente, o receptor precisa decodificar a mensagem, e para isto precisa "lembrar" das partes já recebidas.
Um exemplo simples e artificial do que seria um código convolucional com taxa 2:1, ou seja, cada bit da mensagem é "inflado" para dois bits transmitidos "no fio", e que se baseia nos últimos 4 bits da mensagem:
M[n] = n-ésimo bit mais "antigo" da mensagem M[0] = bit da mensagem a ser codificado y1 = primeiro bit a transmitir y2 = segundo bit a transmitir y1 = M[0] XOR M[1] XOR M[3] y2 = M[0] XOR M[2] XOR 1
Cada bit a transmitir (y1 e y2) é uma função, ou uma convolução, de diversos bits da mensagem original. Exemplo de mensagem M e convolução Y:
M = 0 1 1 0 1 0 0 0 1 1 Y = 01 10 00 10 01 01 00 11 10 00
Embora haja quatro combinações para cada tupla em Y (00, 01, 10 ou 11), a transição entre tuplas só tem duas possibilidades, porque ela só depende do bit correspondente em M.
Por exemplo, a penúltima tupla em Y é igual a 10, ela seria igual a 00 se o penúltimo bit de M fosse zero, mas nunca poderia ser 01 ou 11.
O código Y é convertido num ângulo, que é transmitido pelo modem analógico:
01 = 0 graus 11 = 90 graus 10 = 180 graus 00 = 270 graus
O penúltimo bit de M é transmitidos como um ângulo de 180 graus (correspondente à tupla 10).
Com base no histórico de bits, o receptor sabe que, para o penúltimo bit, só pode receber um ângulo de 180 ou de 270 graus.
Se aparecer algo diferente, trata-se de um erro, mas o receptor pode corrigir o erro com base em algum algoritmo. Por exemplo, se aparecer um ângulo de 285 graus, é seguro supor que 270 era o correto.
(Isto mostra que o código convolucional foi feito para trabalhar "dentro" do modem, muito próximo do meio de transmissão analógico. Não faria muito sentido codificar um arquivo usando esta técnica e mandá-lo anexado num e-mail.)
Já um ângulo de 45 graus é distante tanto de 180 quanto de 270. Neste caso o receptor pode marcar o bit como "incógnita" e esperar a chegada de bits mais confiáveis:
M = 0 1 1 0 1 0 0 0 ? 1 Y = 01 10 00 10 01 01 00 11 ** 00
Com base no histórico, o receptor pode agora resolver a incógnita:
y1 = 0 = 1 XOR ? XOR 0 y2 = 0 = 1 XOR 0 XOR 1 ? = 1
Em resumo, o código convolucional dá condições para que o modem tome decisões "informadas" a respeito dos erros que aparecem, visando corrigi-los.
Este tipo de código foi utilizado em larga escala na época dos modens de 14400 e 28800 bps, nos anos 90. Há quem diga que esta invenção foi a maior responsável pela popularização da Internet, pois permitiu pela primeira vez a transmissão de arquivos relativamente grandes (músicas, imagens).
A época áurea do código convolucional já passou. Nos dias atuais, com hardware e software muito mais rápidos que outrora, a tendência é simplificar o "modem" ao máximo, qualquer que seja o meio de comunicação, usando códigos de bloco para corrigir os erros.
O método OFDM, utlizado em banda larga (ADSL), TV digital, algumas velocidades de Wi-Fi e em muitas outras tecnologias, é um código que ilustra esta tendência de "simplificar" o modem e confiar na correção de erros a posteriori.
O OFDM divide a banda em muitos canais estreitos (podem ser dezenas, ou milhares) e transmite dados numa taxa relativamente baixa em cada sub-canal, utilizando uma codificação bem simples, como QAM-16. Os bits da mensagem são espalhados por todos os sub-canais.
A transmissão por inúmeros canais estreitos tem diversas vantagens: a equalização dos sub-canais pode ser tratada individualmente, a robustez contra ecos e "fantasmas" é melhor, e ruídos impulsivos tendem a afetar um, ou poucos, sub-canais de cada vez — o que se traduz em poucos bits errados por mensagem. Se um sub-canal estiver particularmente ruim, o modem OFDM pode desligá-lo, o que diminui ligeiramente a velocidade total mas economiza erros.
O OFDM em si não corrige erros, mas a viabilidade do OFDM depende diretamente de haver correção de erros, pois os bits errados podem emergir de qualquer sub-canal.
Um tipo de código que lembra vagamente o convolucional, e muito largamente utilizado, é o "n para m". Por exemplo, "2 para 5", onde cada 2 bits da mensagem são "inflados" para símbolos com 5 bits:
bit símbolo 00 -- 01100 01 -- 10100 11 -- 10010 10 -- 11011
Quando utilizado, este tipo de código está embutido na especificação de hardware (por exemplo, Ethernet) e o software nunca toma conhecimento de sua existência. Ele proporciona as seguintes vantagens:
Uma tecnologia de redundância que tem certo parentesco com correção de erros é a utilizada em RAID 5 e RAID 6 — diversos discos rígidos que trabalham de forma coordenada de modo a simular um único grande volume do ponto de vista do software.
RAID 5 usa um disco adicional de "paridade" — se há, digamos, três discos com dados, um quarto disco contém os bits de paridade sobre os dados dos três primeiros:
b(4) = b(1) XOR b(2) XOR b(3) Exemplo: b(4) = 1 XOR 1 XOR 0 = 0
Se por acaso um dos discos rígidos parar, o volume não perde dados, porque os bits do disco quebrado podem ser reconstruídos usando a paridade. Supondo que o disco 2 quebrou:
b(2) = b(1) XOR b(3) XOR b(4) b(2) = 1 XOR 0 XOR 0 = 1
Enquanto o operador providencia a instalação de um disco novo no lugar daquele que quebrou, o volume continua funcionando, mais lentamente.
Assim que um disco bom é instalado, ele é preenchido com os dados originais tão rapidamente quanto possível. O RAID 5 lida apenas com uma falha de cada vez; duas falhas derrubariam o volume.
Não deixa de ser esquema de correção de erros, porém devemos fazer uma fina distinção aqui: o sistema sabe qual disco falhou, e portanto qual o bit que deve ser reconstruído. É uma "deleção" (erasure), não um erro propriamente dito.
O RAID 5 não lida com erros propriamente ditos (por exemplo, se um bit 1 virou 0). É esta característica que permite ao RAID 5 recuperar-se de uma grande perda de dados usando simples paridade.
RAID 6 faz uso de duas paridades (a segunda paridade calculada usando-se polinômios) de modo a suportar a perda simultânea de até dois discos.