 Error detection and correction
Error detection and correction
Error detection and correction
Error detection and correction
Error detection and correction (EDC) algorithms are vital in our present time. Absolutely all communication channels depend on EDC to function, and information technology relies on it to achieve the current degree of trust. Imagine if a money wire transfer implied in a chance of 1:1000 of being corrupted; nobody would use it.
In fact, an error that goes undetected is a showstopper problem when money is involved. In other areas like video or audio, a sizable error rate is tolerable. Because of that, our first metaphor to explain EDC algorithms comes right from the banking industry: the check digit.
Everybody knows check digits, they are ubiquitous in bank account numbers, billes, checks, and many other codes. For example, this hypothetical bank account:
1532-6
The main number, the "real" account, is 1532; the check digit 6 is normally the result of an arithmetical operation executed over the main number.
Everybody knows check digits (CDs) and sometimes they are a nuisance. But not everybody knows why they exist: to catch typing mistakes. The CD value depends on the other digits; if some digit is mistyped, the calculated CD won't match the main number and the error is detected.
For example, if we employ the "modulo-11" algorithm, CD of account 1532-6 is calculated like this:
1 5 3 2 x 5 4 3 2 ------------------- 5 + 20 + 9 + 4 = 38 38 / 11 = 3, remainder of divisiion = 5 11 - 5 = 6 check digit = 6
If, instead of 1532-6, the typist enters 1523-6 (and the correct CD for 1523 would be 1523-7) the system detects the error and rejects the account. But the system can't tell which digit is wrong. It doesn't even know if the intended account was 1532 or 1523. This algorithm can't correct errors.
At first glance, it seems very easy to put together some CD algorithm. Insteda of using modulo-11, we could simply sum all digits, right? Wrong... A simple sum would not catch the error exemplified above, since 1+5+3+2 is equal to 1+5+2+3.
The "perfect" CD algorithm fulfills many demands:
No algorithm can fill all these demands completely, but modulo-11 is pretty close. There are other algorithms that take the keyboard layout into account, and the typical typing errors that such layout tend to induce, but such CDs are table-based while modulo-11 is a very simple calculation. Because of that, it is the most commonly used for decimal numbers.
Some numbers are augmented with two check digits. In theory, they can catch 100% of one-digit and two-digit erros, and 99% of bigger errors.
Some codes (perhaps Security Social Numbers?) are generated in a way that all digits are interlinked in order to prevent simple frauds, but generating tamper-proof codes is a subject for cryptografy, outside the scope of this article.
Modulo-11 can detect every digit swap error because it multiplies every digit by a different "weight" (2, 3, 4, 5, 6, 7, restart in 2...) and adjacent weights are relatively prime, so swapping any two digits will yield a different CD.
Note that, in our example accounts, the "naked" number is 4-digit, which translates to 10,000 possible combinations. The number with CD has five digits, or 100,000 combinations. But, of these 100,000 numbers, 90,000 are invalid accounts. That's how a CD can catch 90% of any typing error.
But modulo-11 catches 100% (all!) single-digit erros, not just 90%. That's the most difficult property to secure, and the most important to understand.
In order to catch all single-digit errors with a single CD, we must guarantee that every account number is different from the others in at least two digits. That means, the Hamming distance between two valid account numbers is at least 2.
Numbers that differ in a single digit are "neighbors"; the Hamming distance between them is, obviously, equal to 1. Example:
1523-6 .. 1523-7 valid invalid
We can imagine that there are "ways" between any two numbers that differ in two digits or more. The "way" will pass from neighbor to neighbor, replacing one digit per hop:
1532-6 .. 1532-7 .. 1522-7 .. 1523-7 1532-6 .. 1522-6 .. 1523-6 .. 1523-7 valid invalids valid
As the example tried to show, there is more than one way between two valid numbers. What matters is the minimum "distance", that by the way is DH=3 in the example above. Also, given that initial and final numbers are valid accounts, the intermediate neighbors are forcibly invalid.
Two different accounts naturally have at least one different digit in account number (e.g. 1523 e 1524). A second dissimilar digit must be generated by the check digit.
The modulo-11 algorithm yields a near-100% guarantee that, if any two accounts differ in a single digit, their check digits will also be different. This gives us a minimum Hamming distance of DH=2, which allows us to detect any single-digit error.
Typing a number with some error yields an account with DH=1, that is, a neighbor of a valid account — an the immediate neighbor of a valid number must be invalid, as valid numbers are always 2 hops apart.
Modulo-11 supplies the additional feature of increasing the minimum Hamming distance to DH=3 for numbers that are different in two digits, owing to a digit swap (inversion). Such numbers are already different in two digits, and CD will be also different to secure three different digits.
For example, the accounts 1523 and 1532 are DH=2 already, but modulo-11 yields differente CDs for them, which secures DH=3 and allows us to catch 100% of typing inversions (which are a kind of two-digit errors). "Ordinary" two-digit erros are caught with (theoretical) 90% efficienty.
This protection against inversions is important because it is a common typing error, so modulo-11 fulfills its use case very welll. But this feature has a price: the detection rate of "ordinary" errors of two digits or more is forced a bit below 90%.
In theory, as we said before, single CD catches 90% of all errors. But modulo-11 yields eleven CD possibilities (0 to 10) while the actual CD must be a number (0 to 9). The eleventh possibility is cast into 0 or 1, derating the error detection a bit.
Some institutions actually use some additional character like "X" for the eleventh check digit. In this case, the modulo-11 efficiency goes back up to 90%.
With a suitable "check digit" algorithm, we can go beyond error dectection; we can actually correct erros without retyping or retransmission.
At first glance it sounds like whichcraft but it is a natural consequence of Hamming distance. Consider an example "path" between two valid accounts, with a triple check digit (I will explain soon why it needs to be triple):
1523-356 .. 1524-356 .. 5524-356 .. 5524-396 .. 5524-390 valid invalid invalid invalid valid
Using three CDs, we can guarantee a minimum Hamming distance of DH=4 between two valid accounts. In order to correct a single wrong digit, we simply adopt the "nearest" valid number.
For example, if we receive the number 1524-356 (invalid), we adopt 1523-356 in its place, since they are neighbors. In the other hand, if we had received 5524-396, we would adopt 5524-390 since it is the nearest valid code.
But, in the case of invalid number 5524-356, we cannot correct the multiple-digit error, since this code is equally distant from 1523-356 and 5524-390. We detected the error but it is beyond correction capabilites of this code.
This is a trait of every error-correcting code: it ceases to correct errors beyond a certain error rate (about half of the Hamming distance). The formulas are:
h = Hamming distance d = h-1 c = (h-1)/2 Example: h = 4 d = 4-1 = 3 (detects 100% of 1, 2 or 3-digit errors) c = (4-1)/2 = 3/2 = 1 (corrects 100% of single-digit errors)
It is important to mention that the code "strength" does not depend on the numbers's length. The valid codes might be 400 digit instead of 4, and the error-correcting capability is still the same. Only the Hamming distance matters.
This is the theory, but finding an algorithm that generates such error-correcting codes is not simple. The biggest challenge is, given an invalid number, find the nearest valid code in order to proceed the correction.
We have employed decimal numbers so far, and there are error-correcting codes for decimal numbers, but they are not ideal. Such codes work better for binary numbers.
To be fair, there aren't many use cases for decimal error-correcting. In case of typing, it is simple enough to ask for re-typing. Error correction has other use cases:
In all these cases, binary codes are more convenient.
Even when we replace decimal by binary system, the basic mechanisms don't change. Hamming distance is still the staple of error detection and correction.
The big change is how the strength of a given code is calculated. For example, a decimal check digit can detect 90% of random errors, while a binary check digit (also called parity bit) detects only 50% of such errors.
This happens simply because a decimal digit contains more information than a binary digit (bit); a decimal CD has 10 possibilities, while a bit has only 2. A "double CD" would catch 99% of errors in decimal, but only 75% in binary. The detection power is calculated like this:
n = number of check digits or parity/checksum bits p = probability of detecting errors of more than "n" digits b = radix (binary=2, decimal=10) p = (b^n-1)/b^n Example: 2 decimal digits p = (10^2-1)/10^2 = (100-1)/100 = 99/100 = 99% Example: 16 binary digits, or 16 bits (like in CRC-16) p = (2^16-1)/(2^16) = 65535/65536 = 99,9984%
Codes with few bits are relatively weak, but it is very cheap to use 16, 32 or even 128 bit codes, and the code gets exponentially stronger.
We are now left with the task of finding suitable algorithms for error detection/correction in binary system.
At the dawn of IT, the error detector of choice was the parity bit. It is still present in legacy serial communications, and in some types of RAM memory. Most current tecnologies use stronger codes e.g. CRC or Reed-Solomon, that we will visit in time.
The idea of parity bit is to make sure that every message fragment (e.g. a byte of 8 bits) possesses an always-even or always-odd number of "1" bits. (This means that we have two "types" of parity to choice from.)
In case of the "even" parity, if there is an odd number of enabled bits in a byte, the parity bit will be "1" to round it up. Otherwise, the parity bit is "0".
Implementing parity in hardware is incredibly simple, it is just a matter of "summing up" all bits with XOR ports (and invert the result if we want odd parity).
It is pretty clear that parity detects 100% of single bit errors, and 50% of other kinds of errors. It is a pretty weak scheme, too weak if se consider the redundancy that it generates (from every 9 bits transmitted, 1 is parity, which is 12.5% of the bulk). Parity is only a sensible option when error occurence is very low and the detection speed is paramount (like in RAM).
Interestingly, parity is a corner case of a better algorithm: CRC. A CRC code of 1 bit is parity.
As we saw, modulo-11 is a near-perfect scheme for error detection in decimal number system. We need something similar for binary numbers.
It must be similar but must also be different, since the remainder of a binary division is either 0 or 1, it does not vary much and would yield a poor code.
The time-proven CRC employs remainders of divisions (modulo) but it divides polynominals, not numbers. The remainder of a polynomial division can be as variable as desired, it is just a matter of choosing a good divisor.
From CRC's point of view, a binary number is a polynomial:
1000101 = x^6 + x^2 + 1
On top of handling binaries as polynomials, CRC does all arithmetical operations in a GF(2) field, in which only two values exist: 0 and 1.
GF(2) field: 1 + 1 = 0 0 - 1 = 1 2n = 4n = 6n = 8n = ... = 0 n = 1n = 3n = 5n = 7n = ...
Note that, in every GF(2) arithmetical operation, an even result is cast to 0, and an odd result is cast to 1 (be it positive or negative).
The most curious aspect of CRC is how easy it is implemented in hardware, with just a handful of XOR ports. The polynomials are actually a mathematical device that allows us to proof that it works for error detection.
The strength of CRC codes depend solely on the chosen divisor, also called "generator polynomial". The basic prerequisite for the divisor is to possess the terms x^n and 1, where "n" is the number of "check digit bits" that we want to produce and add to the message. For example, a CRC of 16 bits needs a generator polynomial of 17 bits, with at least the leftmost and rightmost bits set to 1.
We expect that a 16-bit CRC detects 100% of errors up to 16 bits. But the realization of this power depends on the polynomial generator's quality. For a 16-bit CRC, there are 2^15=32768 candidates and most of them are weak — that is, they yield codes that will miss many errors.
In practice, to avoid a poor choice, most implementations employ well-known polynomials. For example, 0x11021 is often used to generate 16-bit CRCs. The "nickname" of this number if CRC-16 CCITT, since it was selected by the CCITT standards body (nowadays ITU-T).
Since the leftmost (MSB) bit of generator must be 1, it is often omitted. So, CRC-16 is often defined as 0x1021; the 0x10000 is added implicitly.
The simplest CRC code is, of course, a 1-bit CRC, and its generator polynomial must be (x + 1). It is equivalent to the even parity bit and detects every 1-bit error as expected.
In order to illustrate how CRC can detect errors, I will use decimal numbers and "normal" division, before a more realistic example is laid out.
Message M = 123456789 Generator polynomial G = 271
If the divisor G has 3 digits, it will yield a code with triple "check digits". To calculate CRC, I make room to the check digits by adding zeros to the message, make the division and subtract the modulo from the message:
M' = 123456789000 CRC = remainder (modulo) of M' / G CRC = 123456789000 % 271 = 3 M'' = M' - CRC = 123456789000 - 3 M'' = 123456788997
The encoded message M'' is sent out, and the reception side executes the same division, by the same generator G. If the message is ok, the modulo must be zero.
To recover the original message, we must remove the rightmost three digits that contain CRC. If CRC is not zero, we must add 1 to the message to compensate for the subtratction in encoding pbase:
123456788997 % 271 = 0 (ok) 123456788 + 1 123456789
This is the basic mechanism of CRC. Even though it is a faux example because we did not divide polynomials, we already see why a good choice of G is crucial.
A bad divisor like G=300 would yield CRCs always equal to 000, which can't detect errors at all. An even G would always generate even-numbered CRCs, therefore wasting half of the possible CRC values.
In the faux example above, the ideal generator would prime just below 1000. (Yes, 271 was also a poor choice, try to discover why.)
In "real" CRC, the good choice is an odd polynomial (that is, ending in "... + 1") that is not reducible to many simpler polynomials. A simple rule to get initial candidates for G, is multiply some irreducible polynomial by (x + 1).
Now we are going to calculate a real, binary CRC with polynomials. To keep it simple enough, I employed an 8 bit message and a 3-bit CRC.
message M = 10011111 generator G = 1001 add three zeros M' = 10011111 000 Converting to polynomials M' = x^10 + x^7 + x^6 + x^5 + x^4 + x^3 G = x^3 + 1
Now we are going to divide M' by G. I was lazy and employed an online polynomial calculator.
remainder of M'/G = - x^2 - x in GP(2) field = x^2 + x binary CRC = 110 M'' = M' - CRC = 10011111 110
M'' is transmitted. At reception side, it is (as a whole) divided by the same G:
M'' = 10011111 110 M'' = x^10 + x^7 + x^6 + x^5 + x^4 + x^3 + x^2 + x M''/G = x^7 + x^3 + x^2 + x remainder (modulo) = 0 M = M'' / 8 = 10011111
The polynomial modulo is equal to zero, this is how we know that M'' was not corrupted in transit. Now let's suppose that some bit in M'' was flipped:
M'' = 10011101 110 M'' = x^10 + x^7 + x^6 + x^5 + x^3 + x^2 + x modulo of M''/G = x = 10
The non-zero modulo means that M'' is not ok.
The GP(2) arithmetic allows for many simplifications. When some polynomial term is multiplied by 2 or by any even number, it vanishes. Negative terms can be taken as positive.
In particular, GP(2) subtraction is equivalent to XOR in this context, and this allows us to execute the whole polynomial division as a sequence of XOR operations:
M' = 10011111000
G = 1001
10011111000 / 1001
-1001 .
---- .
0* if the MSB (leftmost) bit is zero,
01* just drop the next bit from message
011* .
0111* .
1111 MSB=1, subtract again
-1001 .
---- .
0110* .
1100 .
-1001 .
---- .
0101*.
1010.
-1001.
----
0011*
0110 no more bits to drop, the end
0110 = modulo = x^2 + x + 0
This operation is very easily implemented in hardware using a shift register with the size of the desired CRC code (CRC-16 takes a 16-bit shift register) and XOR ports in positions defined by the generator polynomial.
An illustration from Wikipedia illustrates how the shift register "digests" a message and calculates CRC:
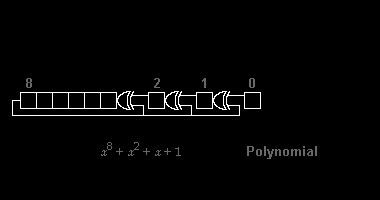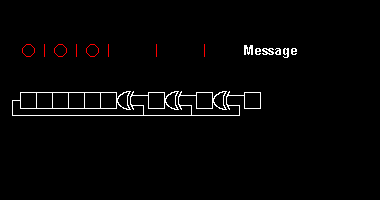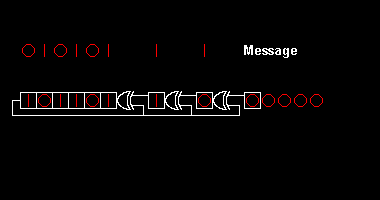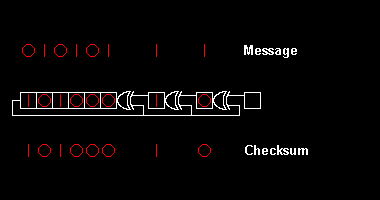
CRC works under the same principles of the humble check digit. CRC-16 adds 16 bits of redundancy to a message (which is just a large 'number'). If the generator polynomial is good, a valid message augmented by CRC will differ from any other valid message by 17 bits at least.
Unfortunately, CRC only allows for error detection; it is not possible to use the code to correct errors, since it is not possible to determine which valid message is 'nearer' of the eventual invalid message that is received.
Actually, there are some techniques to correct 1-bit errors when CRC is present, but they are more subject of research and curiosity. A 16-bit code should be able to correct up to 7 bits, not only 1.
The quest for codes that allow error correction began in the 1940s and current codes have being invented in the fifties and sixties, when research was fueled by the Space Race: Hamming codes, Reed-Solomon codes, BCH codes, etc.
Reed-Solomon is particularly popular, being employed e.g. in CDs and DVDs (note that CDs are 1970s tech) because optical disks can get dust and scratches, so the eventual loss of some information is certain and must be compensated for.
A very simple code (that I actually "invented" as a teenager, not knowing how Hamming codes worked) employs a criss-cross of parity bits, and is capable of correcting any 1-bit error.
Example of 16-bit message, laid out as a 4x4 matrix:
message | vertical parity
0 1 1 0 | 0
1 0 0 0 | 1
0 0 0 0 | 0
1 1 0 1 | 1
------------+
0 0 1 1
horizontal parity
Cross-parity can correct any single error, since the parities indicate the coordinates of the bad bit:
0 1 1 0 | 0
1 0 0 0 | 1
0 0 1! 0 | 0 <-- wrong parity
1 1 0 1 | 1
------------+
0 0 1 1
^
wrong parity
If parity indicates an error in just one dimension, the corruption ocurred in the parity bit itself, not in the data:
0 1 1 0 | 0
1 0 0 0 | 1
0 0 0 0 | 0
1 1 0 1 | 1
------------+
0 0 0! 1
^
bad parity
Unfortunately, this code cannot solve two (or more) errors, since then the error position becomes ambiguous:
0 1 1 0 | 0
1 A B 0 | 1 <-- wrong parity
0 B' A' 0 | 0 <-- wrong parity
1 1 0 1 | 1
------------+
0 0 1 1
^ ^
wrong parities
In the example above, we know that either the A,A' or B,B' bit pair is wrong, but we can't tell which one.
The Hamming code is conceptually similar to the homebrew code developed above. It is based in crossed parities, can correct every 1-bit error and detect every 2-bit error.
This class of codes was invented by the mathematician Richard Hamming, that also invented the concept of "Hamming distance" mentioned at the beginning of this article.
It was the first error-correcting code actually used in applications. It is not very efficient (corrects few errors in relationship to the extra bits it takes) but it is easy to understand, easy to implement and works very fast in hardware.
It is still employed in applications where few errors are expected, all of them 1-bit at most, and the correction circuit must be extremely fast e.g. ECC RAM memories.
Hamming code does increase in efficiency as the message size increases: 3 parities are needed for a message up to 4 bits; 4 parities for up to 11 bits, 6 parities for up to 57 bits and so on. This is the scheme for an 8-bit message:
Bit position 1 2 3 4 5 6 7 8 9 10 11 12 Bits p1 p2 m0 p3 m1 m2 m3 p4 m4 m5 m6 m7 ---------------------------------------------------- Parity 1 (p1) x x x x x x Parity 2 (p2) x x x x x x Parity 3 (p3) x x x x x Parity 4 (p4) x x x x x
One key thing: the parity bits (p1..p4) are intermingled with the original message bits (m0..m7). This allows the parity bits to protect themselves. The parity bits are inserted at bit positions that are powers of 2 (1, 2, 4, 8) assuming that bit position starts at 1.
Another thing: the parity map is an ascending binary sequence. For example, the bit in position 5 influences the p1 and p3, and "101" is 5 in binary. This property is used directly to correct an error. If the received message has parities 1 and 3 wrong, it must be because bit 5 is bad, and it is mended by flipping bit 5.
At least two parities must be wrong for a message bit to be wrong. If a single parity is wrong, it means that the parity itself was corrupted, not the message.
Example of message encoding with even parity:
Message: 01101101 (109 decimal) Parities/Bits p1 p2 0 p3 1 1 0 p4 1 1 0 1 ---------------------------------------------------- p1 =0 0 1 0 1 0 p2 =0 0 1 0 1 0 p3 =1 1 1 0 1 p4 =1 1 1 0 1 Encoded message: 000111011101
Now let's suppose the message was corrupted:
Received encoded message: 000101011101 Parities/Bits p1 p2 0 p3 0 1 0 p4 1 1 0 1 ---------------------------------------------------- p1 WRONG 0 0 0 0 1 0 p2 ok 0 0 1 0 1 0 p3 WRONG 1 0 1 0 1 p4 ok 1 1 1 0 1 By inverting fifth bit (second bit of the original message), all parities are ok.
Another case, when a parity bit is corrupted:
Received encoded message: 010111011101 Parities/Bits p1 p2 0 p3 0 1 0 p4 1 1 0 1 ---------------------------------------------------- p1 ok 0 0 1 0 1 0 p2 WRONG 1 0 1 0 1 0 p3 ok 1 1 1 0 1 p4 ok 1 1 1 0 1 By inverting the third bit (the parity p2 itself), all parities are ok.
Reed-Solomon is a non-binary error correcting code. It is non-binary, that is, the individual "digits" (called symbols) are not bits, but bundles of bits.
It could be, for exemple, 8-bit bundles (i.e. bytes). In this case, symbols can take 256 different values. In order for error correction to work, the message's total length must be not greater than symbol count — in the example, the message must be no bigger than 256 bytes. The bundling of bits to form symbols must be chosen accordingly to the message size.
The Reed-Solomon (RS) code generation resembles CRC a lot: the original message M is taken as a polynomial. It is left-shifted and divided by the generator polynomial G. The remainder of this divison is the RS code:
m = bits per symbol k = code length M' = M x 2^k = M >> k C = M' % G M'' = M' - C arithmetical operations executed in GF(2^m) field 8 bits per symbol = GF(256)
The biggest difference from CRC is that polynomials' coefficients are not just 0 or 1 like CRC: they take symbols' values. If symbol is 8-bit, coefficients can vary from 0 to 255.
The generator G is not chosen "manually" as in CRC. It is systematically built with basis on symbol's length and the correction code's length. For an encoding with 8-bit symbols and 32-bit correcting code (which is 4 symbols), G must have four roots.
The error detection phase of RS is again similar to CRC. A polynomial division with no remainder means that message is error-free.
In case there is a remainder, it is used to find the errors and correct them. This part of RS is very complicated. This article describes the process in a very didactic way, even though it does not make the subject magically easy. I will repeat some highlights here.
If M'' has no errors, the remainder of M''/G is zero. This means that M'' is actually a multiple of G, and being so, M'' has the same roots as G — remember that G is built such that symbols are G's roots. Therefore, the roots of M'' are symbols as well.
If the received message has errors, it can be defined as a "sum" of the correct/expected message with an error polynomial E:
M''' = M'' + E M'' % G = 0 M''' % G = S S = "Syndrome" somehow related to E E = a1.x^b1 + a2.x^b2 + ... a1, a2, ... = deviation coefficients of corrupted symbols b1, b2, ... = positions of corrupted symbols M'' = M''' - E
If we can determine E, we can subtract it from the corrupted message, thereby correcting the errors. In order to find E, we must find the unknown values of a1, a2, ... as well as b1, b2, b3...
We don't know E (yet), but we have S, the "syndrome" that is the remainder of M'''/G. But S and E are related; the error is a multiple of the syndrome. Calculating either S(x) or E(x) yields the same when x is some root of G:
M'' % G = 0 M''' = M'' + E M''' % G = S (M'' + E) % G = S M'' % G + E % G = S E % G = S If x = root of G, E(x) = S(x)
Thanks to this relationship, we can make an equation system, one equation for each root of G, to solve the unknown values of E.
Note that, if we get 2 errors, the E polynomial has 4 unknowns (twice the error count), and to find 4 unknowns we must have a system of 4 equations. To make 4 equations, the generator polynomial G has to have 4 distinct roots. This is the mathematical reason why an error-correcting code is weaker to correct errors than to detect them (a 16-bit code can detect up to 16-bit errors but can correct at most 8).
In some cases, the corrupted symbols are annotated as such by the underlying hardware. In this case, the RS code can correct more errors, since the error positions are known in advance, leaving fewer unknowns to solve.
The original Reed-Solomon paper just specified how errors could be corrected. It did not specify how it could be implemented in an efficient way. Efficient algorithms for RS decoding were invented later.
Error correction was invented to avoid data loss, but it can also be used in a Machiavelic fashion, to squeeze the most of a channel's capacity.
The strategy is roughly as follows: suppose you have a channel that can send 10 bits/s without errors, or 20bps with 10% error rate. If I can't use any error-correcting code, I am forced to take the 10bps option.
In the other hand, if I can do error correction, I can send data at 20bps using some code with 25% of redundancy (every 100 bits of payload become 125 bits on wire). Thus I can guarantee that almost all errors are elided and I can send the payload at 16bps (20bps minus the parity bits added in coding phase) — a gain of 60%.
Nowadays, every communication technology uses some strategy of error correction to make the most of the media, be it WiFi, 3G, and even wired connections.