 Os ataques MELTDOWN e SPECTRE
Os ataques MELTDOWN e SPECTRE
Os ataques MELTDOWN e SPECTRE
Os ataques MELTDOWN e SPECTRE
A gente da informática já está acostumada com babados fortes acontecendo justamente na véspera de fim-de-semana, feriadão ou férias há muito programadas. Entre Natal e Ano-Novo o grande comentário era um possível bug nos processadores Intel que permitiria a invasão de qualquer computador com "Intel Inside". O que sabíamos de concreto, era que os desenvolvedores de todos os sistemas operacionais estavam trabalhando duro para liberar atualizações o mais rápido possível, enquanto os detalhes dos problemas nos processadores estavam "sob embargo", ou seja, mantidos em segredo.
Ontem, esses detalhes foram publicados neste site, na forma de artigos científicos. O que era um problema virou dois. O ataque apelidado MELTDOWN só afeta processadores Intel — ou pelo menos foi o que se conseguiu comprovar até agora.
Já o ataque aparentado SPECTRE afeta praticamente todos os processadores modernos, embora seja um ataque considerado menos grave — também por ora.
Neste artigo, pretendo explicar de forma acessível como estes ataques funcionam e porque devem ser motivos de preocupação.
O MELTDOWN pode ser comparado com um detector de mentiras. Em tese, dizer uma mentira custa um esforço mental maior do que falar a verdade, e a diferença pode ser detectada.
Considere o seguinte pseudo-programa em C:
uint8_t *p = ENDERECO_DO_KERNEL;
uint8_t a = *p; // quebra o programa
int b = a + 3; // nunca é executado (ou talvez seja?)
printf("%d\n", b); // nunca é executado
O código acima tenta ler um byte de uma área de memória privilegiada, que pertence ao kernel do sistema operacional. Em seguida, faz uma operação aritmética com base no valor lido, e imprime o resultado. Obviamente, o acesso à memória do kernel é proibido e o programa nunca imprime nada.
Considerando que o programa quebra, a operação aritmética também não aconteceu, ou parece não ter acontecido, afinal o resultado nunca pôde ser observado.
Porém, todo processador moderno executa várias instruções em paralelo e de forma especulativa, ou seja, mesmo correndo o risco do resultado ser descartado. No exemplo acima, o processador provavelmente chegará a ler o byte do kernel e fará a soma antes de descobrir que o acesso é inválido.
Naturalmente, quando a violação é detectada, todos os efeitos colaterais da instrução são descartados. No exemplo acima, "b" depende de "a", que depende do acesso proibido. Nenhuma das variáveis vai reter seus valores "especulados". Mas, talvez, haja algum outro efeito colateral das instruções especuladas?
Um exemplo besta: se a CPU esquentasse muito depois de especular as instruções acima quando o resultado de "b" fosse ímpar (e portanto "a" fosse par), poderíamos então "ler" o bit 0 LSB de qualquer byte da memória do kernel. Seria demorado, pois teríamos de esperar a CPU esfriar depois de cada tentativa. O uso desse "vazamento de bit 0" também seria um tanto limitado. Mas já teria algumas conotações graves, no mínimo para a criptografia.
"Ah, mas o programa quebra, como ele vai ler a temperatura da CPU?" Bem, sempre podemos rodar um programa separado para ler a temperatura. Porém, é mais fácil tratar a violação de acesso dentro do próprio programa de modo que ele não quebre. No UNIX fazemos isso tratando ou ignorando o sinal SIGSEGV, e no Windows usamos o SEH.
Podemos tentar ler milhares de bytes do kernel a cada segundo impunemente. Só falta descobrir um "vazamento": um efeito colateral que revele o valor desses bytes.
O ataque MELTDOWN "vaza" os bytes lidos trazendo uma certa página de memória para o cache. Veja o seguinte pseudo-código C:
char *area_de_memoria = malloc(256 * 4096);
... expulsa area_de_memoria do cache da CPU ...
uint8_t *p = ENDERECO_DO_KERNEL;
uint8_t a = *p;
uint8_t b = *(area_de_memoria + 4096 * a);
long long menor_tempo = 9999999999999;
uint8_t a_vazado = 0;
for (int c = 0; c < 256; ++c) {
long long tsc0 = tsc();
char b = *(area_de_memoria + 4096 * c);
long long tsc1 = tsc();
long long tempo = tsc1 - tsc0;
if (tempo < menor_tempo) {
// o menor tempo é conseqüência da especulação
// feita pelo processador com o valor de "a",
// que trouxe a respectiva página para o cache
menor_tempo = tempo;
a_vazado = c;
}
}
printf("O byte %p do kernel é igual a %02x",
ENDERECO_DO_KERNEL, a_vazado);
Em vez de fazer "a+3", multiplicamos por 4096 e usamos como índice para ler uma área de memória legítima. Como dito antes, todos os efeitos colaterais ("a" e "b") são descartados assim que a violação é detectada. Porém, como a especulação corre na frente da detecção de violação, uma página de memória chegou a ser trazida para o cache L1 do processador. Por exemplo, se o byte contido em ENDERECO_DO_KERNEL é igual a 23, o byte (area_de_memoria + 94208) será especulativamente acessado, e esta parte da memória está agora no cache.
Em seguida, o programa tenta acessar cada uma das possíveis posições de "area_da_memoria" que poderiam ter sido acessadas pelo especulador da CPU, cronometrando o tempo de acesso. Se a posição estiver no cache, a leitura demora 5 ciclos de CPU. Se não estiver, demora até 200. É uma diferença pequena, mas que pode ser medida com um relógio suficientemente preciso. Em particular, na arquitetura x86, qualquer programa pode ler o contador TSC do processador — um valor que é incrementado a cada ciclo de clock.
Antes de ler um byte do kernel, precisamos ter certeza que "area_de_memoria" está inteiramente fora do cache da CPU. Não é difícil garantir isso. A arquitetura x86 tem uma instrução específica expulsar memória do cache (clflush) que (incrivelmente) programas comuns podem usar. Na falta dela, pode-se usar a força bruta, acessando uma outra grande área de memória qualquer, que tomará conta de todo o cache.
Como cada tentativa de acesso causa uma violação de acesso e é preciso fazer a cronometragem em seguida, a leitura de bytes do kernel não é muito rápida; os testes preliminares atingiram 2000 bytes/s.
O MELTDOWN é um problema de hardware, um erro de projeto do processador. Até onde se sabe, apenas uma parte (ok, uma grande parte) dos processadores Intel é afetada. A AMD afirmou categoricamente que suas CPUs nunca acessam memória especulativamente sem antes verificar que o acesso é legítimo. Idem para a plataforma ARM. Mas, como se trata de um tipo de ataque bastante novo, pode haver novidades ruins também para os chips não-Intel no futuro.
Uma solução grosseira é desligar o cache de memória na BIOS. Esta solução é recomendada para usuários de MS-DOS. Infelizmente ela reduz muito a performance do sistema, até 80% em alguns casos.
Em sistemas operacionais modernos como Linux e Windows, a solução é tirar completamente o kernel da memória virtual dos processos. (Para entender porque o kernel estava lá, leia a parte final deste artigo.) Isto também causa uma redução de performance, que pode variar de 0% a 30% dependendo da aplicação. Na prática espera-se uma redução modesta, de 5% a 10%.
Para explorar o ataque MELTDOWN, o atacante precisa ter acesso suficiente ao computador para enviar um programa de ataque, e executá-lo. Pode ser por exemplo uma conta Telnet ou SSH, ou um login local.
A priori, um servidor Web só poderia ser atacado se o usuário tiver como fazer upload de um programa CGI. Fora isso, a quase totalidade dos serviços de rede "modernos" não permite upload e execução de programas arbitrários, até porque isto já foi vetor para inúmeros ataques no passado.
Uma grande dor-de-cabeça é a nuvem. A maioria das máquinas na nuvem é virtual, ou seja, compartilha o hardware com máquinas de outros clientes da nuvem. Qualquer "vazamento" de informação no nível de hardware, por menor que seja, tira o sono de fornecedores e clientes de serviços de nuvem.
A princípio o MELTDOWN não afeta supervisores de máquinas virtuais "clássicas", porém a quase totalidade das nuvens usa paravirtualização como Xen ou KVM, cujo desempenho é melhor mas o potencial de vazamento também é maior.
Considere o seguinte pseudo-programa em C, e suponha que o compilador não vai remover o óbvio código morto:
// "a" é um inteiro
// "b" é um segredo que não deveria vazar
if (a != a) {
// nunca é executado (será?)
c = mem[b];
} else {
c = -1;
}
Se um atacante pretende descobrir o valor de "b", uma possibilidade seria forçar a leitura de "mem[b]" e verificar que parte da matriz "mem" foi trazida para dentro do cache, similarmente ao MELTDOWN. Porém, se a condição de execução é sempre falsa, como faz?
Além de executar instruções em paralelo e de forma especulativa, os processadores modernos estimam o caminho mais provável de execução. Esta estimativa pode ser fornecida pelo compilador, e/ou pode ser determinada durante a execução pela própria CPU.
Se o processador executar o código do exemplo acima por algumas vezes, ele anota que o caminho mais provável é pular o primeiro bloco, e já vai executar especulativamente "c = -1" em paralelo com o teste "a != a".
No entanto, a CPU precisa adotar um critério simples e rápido para relacionar uma instrução de condição ("if") a uma estimativa. Critérios como processo, usuário, etc. são de nível muito alto. Na prática, a CPU usa alguns bits LSB do endereço da instrução condicional como "índice".
Este critério pode levar a erros, por exemplo se dois "if" com probabilidades opostas calham de estar em endereços "parecidos" e acabem compartilhando da mesma estimativa. Um deles estará eternamente condenado a ser estimado erradamente. Normalmente, a chance desse conflito acontecer é muito pequena. Mas, e se o conflito for provocado de propósito?
A técnica básica do ataque SPECTRE é "envenenar" a estimativa do caminho de execução. O programa atacante executa várias vezes uma instrução
if (a == a) {
cujo endereço seja "parecido" com a instrução
if (a != a) {
do programa atacado. Quando o programa sob ataque for novamente executado, o processador executará especulativamente a instrução
c = mem[b];
pois foi convencido de que o resultado de "if" seria mais provavelmente verdadeiro. Os efeitos colaterais são descartados assim que o processador descobre que o resultado do "if" é falso, e isto não quebra o programa atacado.
Porém, a página de memória apontada por "mem[b]" foi trazida para o cache por conta da especulação frustrada. Se o programa atacante puder cronometrar o acesso às diferentes partes da matriz "mem", descobrirá o valor provável de "b".
Antes de prosseguir, devo dizer que não é muito fácil para um programa atacar outro desse jeito, pois "mem" não é observável de fora, nem mesmo para descobrir que partes de "mem" estão cacheadas. Um ataque nesta linha é bem mais fácil quando atacante e vítima compartilham memória, ou residem no mesmo processo. Por exemplo, código Javascript rodando num browser.
Como Javascript é transformado em código de máquina pelo JIT dos interpretadores modernos, que também implementam asm.js (nem vamos falar em WebAssembly), é possível escrever código JS em nível tão baixo quanto C, cuja tradução para assembler seja compacta e previsível.
Agora, considere este pseudocódigo, que é o coração do ataque SPECTRE:
var mem = SharedArrayBuffer(1);
var mem2 = SharedArrayBuffer(256 * 4096);
// expulsa mem2 do cache com força bruta
// escolhe "b" fora dos limites 0..<b.length
// envenena a estimativa da condição a seguir
if (b >= 0 && b < mem.length) {
c = mem2[4096 * mem[b]];
} else {
c = -1;
}
// cronometra o acesso às diversas partes de mem2 para
// determinar qual porção está no cache, no mesmo estilo
// do MELTDOWN.
A ideia do código acima é acessar memória "proibida", mas desta vez não é memória do kernel, mas sim do próprio processo onde ele está rodando. Poderia ser código Javascript tentando escapar da "caixa de areia", ou código PHP tentando ler a memória do servidor Web. Considerando que uma prova de conceito do SPECTRE foi realmente implementada em JS, vamos considerar este caso.
Se fizermos b=10000000, o valor de mem[10000000] cai fora dos limites do buffer. Se pudesse ser lido, retornaria um byte da memória do browser, violando a "caixa de areia". Tentar fazer isto explicitamente quebraria o programa. Protegemos o acesso inválido com uma condição "if" que é sempre falsa para valores "interessantes" de "b", e assim o programa não pode quebrar.
Normalmente, o processador descobriria logo que a condição é sempre falsa. Porém, se convencermos a CPU que a condição "if" é mais provavelmente verdadeira, a CPU executará especulativamente a linha
c = mem2[4096 * mem[b]];
o que trará uma parte de "mem2" para dentro do cache. Por exemplo, se o byte contido em "mem[10000000]" é 30, a região em torno de "mem2[122880]" será cacheada. Daí em diante, procede-se como no ataque MELTDOWN: mede-se o tempo de acesso das diversas partes de "mem2". A parte com acesso mais rápido provavelmente corresponde ao valor 30.
Infelizmente o SPECTRE afeta todos os processadores modernos, pois todos fazem execução especulativa. O SPECTRE é um ataque mais difícil e provavelmente menos grave que o MELTDOWN, por outro lado não tem uma solução "simples" como o MELTDOWN.
Se você está vulnerável ao MELTDOWN, também estará vulnerável ao SPECTRE. Máquinas com acesso remoto (Telnet/SSH) ou login local são as mais problemáticas, já que o usuário pode rodar qualquer programa.
Mas a maior preocupação é com os browsers, que todo mundo usa e que executam código Javascript "hostil" rotineiramente. Algumas medidas de emergência já foram adotadas, como a remoção do SharedArrayBuffer e diminuição da precisão dos timers até que soluções mais definitivas apareçam. Acredito que todas as demais linguagens interpretadas e/ou que rodam numa máquina virtual são afetadas de algum modo.
Um flanco perigoso é o eBPF do Linux. BPF é código de filtragem de pacotes de rede que é fornecido pelo usuário, mas roda dentro do kernel, de forma análoga a um script JS rodando num browser. Usando a técnica SPECTRE, um script BPF malicioso pode ler toda a memória do kernel, com velocidade semelhante à técnica MELTDOWN. (O bytecode eBPF é de nível mais baixo que o BPF clássico do BSD, então não está claro se o BPF do BSD é um vetor para o SPECTRE.)
Uma vez que o ataque SPECTRE é extensível ao kernel, também pode ser estendido para as máquinas virtuais e para a nuvem, em particular quando se emprega paravirtualização.
Como dito antes, não é muito fácil usar este ataque contra um processo com o qual não se compartilha memória. A técnica descrita no artigo científico criou uma "vítima sintética" para demonstrar a possibilidade de cruzar esta fronteira.
Atacar um processo separado implica em procurar por gadgets, pontos vulneráveis onde existe uma condição que pode ser a) "envenenada"; b) levada a acessar áreas sensíveis da memória; c) influenciada por variáveis externas sob controle do atacante (uma variável de ambiente, o conteúdo de um arquivo, uma passagem de parâmetros, etc.).
Considere o código abaixo, e suponha que ele seja legítimo, ou seja, faça parte de um programa normal:
// a e b são inputs externos, controláveis pelo atacante
if (...a e b estão dentro dos limites...) {
c = mem2[mem[a] + b];
}
Fazemos "a" igual à posição da memória do processo-vítima que vamos ler, e fazemos "b" igual ao endereço de alguma biblioteca compartilhada (DLL). O resto do ataque é semelhante à outra versão: envenenar a estimativa para que a CPU execute a linha com valores inválidos de forma especulativa, e depois verificar qual página da DLL foi trazida para o cache, que será correspondente a um valor de "a".
Como o nome diz, a DLL é compartilhada entre todos os processos que fazem uso da mesma DLL. Assim que o atacante carrega uma DLL em comum com a vítima, isto proporciona a área "mem2" que vaza informação por meio do cache. Em cada processo, a mesma DLL será mapeada num endereço diferente, mas o atacante pode fazer uso de algumas heurísticas para descobrir o endereço na vítima.
Uma desvantagem do gadget acima é que "b" teria de assumir valores muito grandes, positivos ou negativos. Talvez alguma outra parte do programa-vítima filtre valores claramente absurdos de "b". Uma versão ainda mais insidiosa deste ataque é baseada em "saltos indiretos":
// a e b são inputs externos, controláveis pelo atacante
if (...a e b estão dentro dos limites...) {
x = mem[a] + b;
c = tabela[x]();
}
Por incrível que pareça, mesmo que "x" esteja fora dos limites, a CPU ainda tentará executar especulativamente as primeiras instruções do endereço apontado por tabela[x] — desde que acredite que a condição seja provavelmente verdadeira.
Conhecendo um pouco da estrutura do programa-vítima, o atacante pode induzir a vítima a trazer esta ou aquela página de uma DLL para dentro do cache em função do valor de "mem[a]". Uma vantagem do gadget de salto indireto é que os valores de "a" e "b" podem ser pequenos, e têm mais chance de passar por eventuais filtros.
Por ora não existe uma bala-de-prata para o SPECTRE porque todos os processadores modernos de uso geral fazem execução especulativa de instruções — e vão continuar fazendo, já que 80% de sua performance depende disso.
Então cada software terá de adotar alguma solução mitigatória. Os browsers serão o principal foco no futuro próximo, assim como o eBPF do Linux e técnicas de paravirtualização como KVM e Xen.
Uma solução mais geral para o caso de sistemas timesharing, onde os usuários podem executar quaisquer programas, é difícil. Assim como os atacantes também acharão difícil achar os tais gadgets para explorar. Mas já se discute mudanças em compiladores C para que os gadgets baseados em saltos indiretos nunca sejam produzidos.
Há vários anos, o layout da memória virtual dos processos é "bagunçado" ou randomizado (ASLR). Isto dificulta os clássicos ataques de buffer overflow que eram a grande preocupação de segurança nos anos 1990. Mais recentemente, a mesma coisa foi implementada no nível do kernel do sistema operacional (KASLR) de forma preventiva. O ataque ROWHAMMER, que também explora defeitos de hardware, depende de se conhecer o layout da memória; o KASLR não evita o ataque mas torna-o mais improvável.
Ou assim se pensava. Na metade de 2017, a universidade de Graz (Áustria) mostrou que era possível "vazar" alguma informação da memória do kernel. Cronometrando-se o tempo que leva um acesso proibido, pode-se determinar se o kernel está ocupando aquele trecho de memória. Por si só é uma informação de pouca valia, mas colocou em dúvida a eficácia do KASLR como ferramenta de segurança.
O mesmo time previu que ataques mais perigosos poderiam ser concebidos segundo as mesmas técnicas, e propôs uma solução preemptiva: o recurso de segurança KAISER, que é simplesmente a remoção opcional do kernel da memória virtual dos processos, com a respectiva penalidade de desempenho.
Inicialmente, o KAISER teve uma recepção morna, porém a atividade em torno do assunto cresceu subitamente no final de 2017, sugerindo que a previsão inicial do time austríaco estava afinal correta e um ataque concreto tinha sido descoberto.
O ataque SPECTRE é aparentado ao MELTDOWN e descendente da mesma ideia inicial.
Esta seção destina-se a quem ficou se perguntando por que afinal de contas o kernel reside na mesma memória que um programa comum, o que viabiliza o ataque MELTDOWN.
Nos sistemas operacionais de uso geral modernos (Windows, Linux, etc.) cada programa em execução — denominado "processo" — reside num enorme espaço de memória, denominado memória virtual (VM). Num computador de 64 bits, este espaço tem 264 bytes.
Cada processo tem sua própria memória virtual ou VM, isolada dos demais, o que dá a cada processo a ilusão de que ele é único. O próprio kernel ou núcleo do sistema operacional existe dentro de memória virtual.
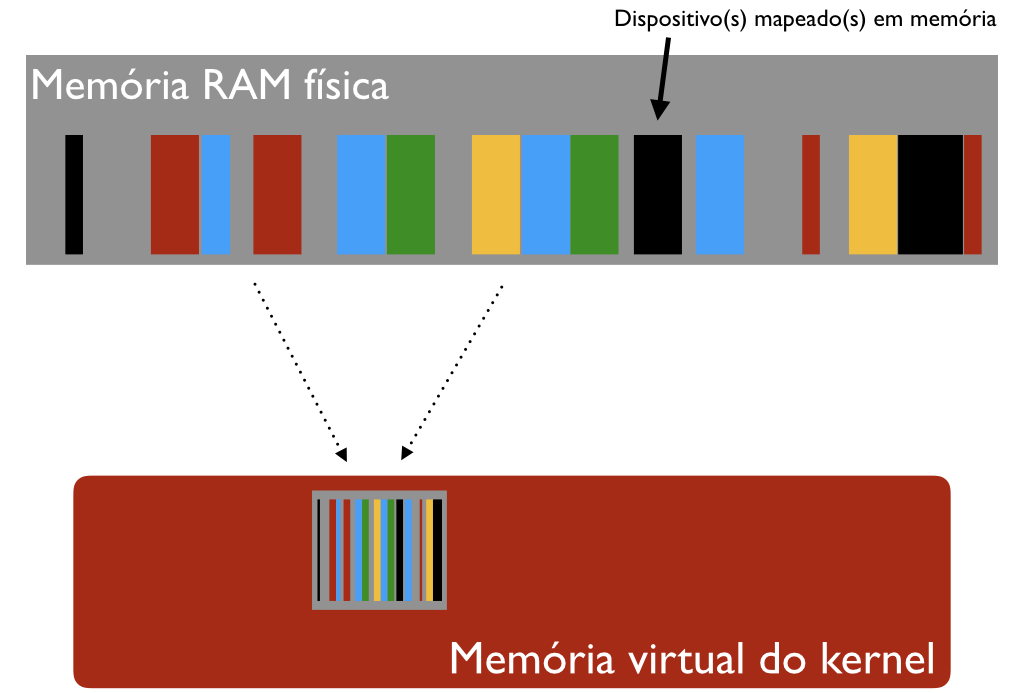
Porém, a VM do kernel (em vermelho) aparece na VM de todos os processos, na mesma posição e com o mesmo conteúdo. Mais adiante vou explicar o porquê disto.

Mas a VM é uma ficção. A memória RAM física, pela qual você paga caro, existe em quantidades muito menores, em torno de 234 bytes (8 gigabytes) num PC atual. Os fragmentos ou páginas das memórias virtuais dos diversos processos, bem como as páginas do kernel, estão espalhados pela RAM.
O mapeamento entre memória real e memórias virtuais é executado em parte pelo próprio processador, e em parte pelo kernel.
Há mais duas coisas que falta explicar a respeito da figura acima.
Primeiro: toda a RAM física está mapeada na memória virtual do kernel. Isto é possível porque a RAM física é sempre muito menor. É por isso que a figura mostra uma "miniatura" da RAM física dentro do kernel (lembrando um código de barras).
Desta forma, ainda que o kernel rode dentro de um contexto de VM, ele tem acesso direto à RAM inteira, sem precisar fazer nenhuma tradução de endereço. O código do kernel fica mais simples.
Segundo: as listras pretas dentro da RAM física são "dispositivos mapeados em memória". Nem tudo que tem um endereço físico de RAM é RAM de verdade. Pode ser a memória da placa de vídeo (que espelha o que está sendo exibido na tela). Pode ser a placa de som. Nos Arduinos da vida, até os pinos de I/O são acessíveis via endereços de RAM.
Dispositivos mapeados em memória são acessíveis ao kernel (e a processos com autorização suficiente) como se fossem memória comum. Tem mais detalhes nessa história, mas a moral é a seguinte: quem tem acesso a todos os endereços da RAM, tem controle do hardware.
Então, se a VM de um processo contém o kernel, que por sua vez contém toda a RAM física (e, por tabela, o hardware), devemos fazer uma atualização da primeira figura:

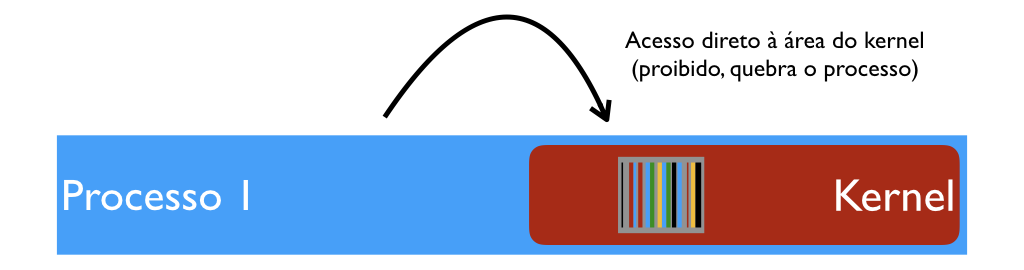
Apesar do kernel estar dentro da VM do processo, o processo não pode acessar esta parte da sua própria memória. Se tentar, uma exceção é levantada, e tipicamente isto causa a morte do processo.
Esta segurança é garantida pelo hardware da CPU. Cada tipo de CPU estipula um certo número de níveis ou "anéis" (rings) de privilégio, e cada página de cada memória virtual tem um nível de privilégio. Se a CPU estiver executando código de uma página Ring 3, este código não pode acessar páginas Ring 2, 1, ou 0. Já código Ring 0 (como o do kernel) pode acessar todas as demais.
Porém, há mecanismos de elevação de privilégio. Quando o processo executa uma chamada de sistema (e.g. pede para ler um arquivo do disco), a chamada abre a memória virtual do kernel para que este atenda à chamada.
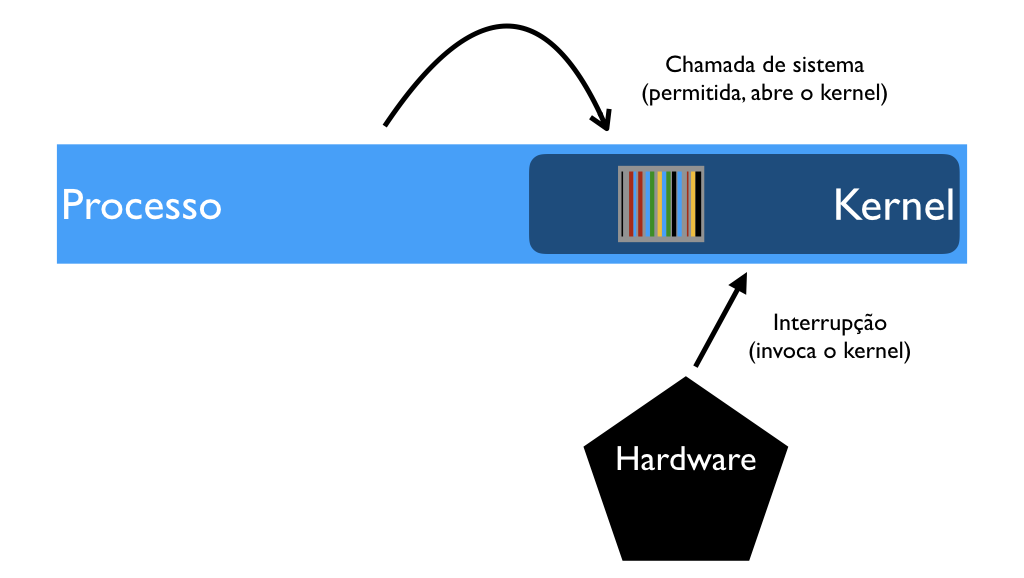
O mesmo acontece numa interrupção, ou seja, quando algum dispositivo de hardware precisa da atenção do kernel (e.g. o disco quer entregar um pedaço do arquivo). A VM em uso no momento é "aberta" para que o kernel trate a interrupção.
Com um detalhe: mesmo que o processo em execução não tenha nada a ver com a interrupção (e.g. não foi ele quem pediu para ler o disco), é a VM desse processo que vai tratar a interrupção, e o resultado é guardado em algum lugar para ser entregue ao processo certo mais tarde.
Assim, tanto na chamada de sistema quanto no tratamento de interrupção, evitamos o "chaveamento de contexto", ou seja, a troca do mapa de VM. O chaveamento é uma operação demorada, e muitas trocas são evitadas quando o kernel está mapeado dentro de cada processo.
Infelizmente, o MELTDOWN permite que um processo leia o conteúdo do kernel, e portanto de toda a RAM, inclusive o conteúdo de outros processos, sem permissão. Para evitar isso, o kernel deve ficar em uma VM separada dos demais processos. E assim sendo, cada interrupção e cada chamada de sistema provocará dois chaveamentos de contexto, ao entrar e ao sair do kernel.
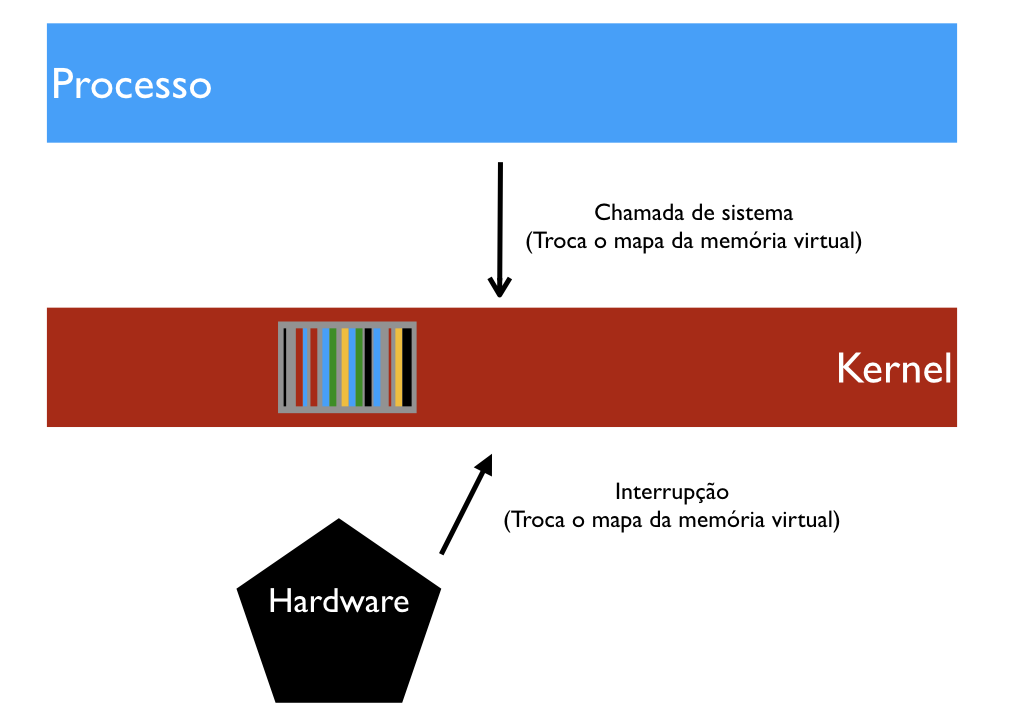
A queda de performance depende de quão freqüentemente os processos chamam o sistema. Processos do tipo processamento de vídeo, mineração de Bitcoin, etc. quase não seriam afetados, enquanto bancos de dados (que usam o disco o tempo todo) devem sofrer até 30% de quebra.