 The MELTDOWN and SPECTRE attacks
The MELTDOWN and SPECTRE attacks
The MELTDOWN and SPECTRE attacks
The MELTDOWN and SPECTRE attacks
Seasoned IT folks are accustomed with nasty issues happening right before weekends, bridged holidays or long-planned vacations. The days before New Year's Eve were full of gossip about a possible hardware bug in Intel processors that would render vulnerable any computer with "Intel Inside". What we knew for sure was that developers from all major operating systems were working hard to release updates as fast as possible, while the details of the problem were "under embargo", that is, kept secret.
In Jan 04, the details were made public on this site, in the form of scientific articles. We expected one big problem; there are actually two big ones. The attack nicknamed MELTDOWN only affects Intel CPUs — at least provably, for now.
On the other hand, the SPECTRE attack affects most modern CPUs, even though it is more difficult to carry out and considered less dangerous — for now, as well.
In this article, I intend to explain, using accessible language and terms, how these attacks work, and why people should be concerned.
MELTDOWN can be loosely compared to a lie detector. In theory, telling a lie takes a bigger mental effort than telling the truth, and the difference is detectable.
Consider the following pseudo-program in "C":
uint8_t *p = SOME_KERNEL_ADDRESS;
uint8_t a = *p; // crashes the program
int b = a + 3; // never executed (are you sure?)
printf("%d\n", b); // never executed
The code above tries to read a byte from a privileged area, that exists inside the process' memory but belongs to the operating system's kernel. Right after, it does some arithmetic with that byte and prints the result. Reading the kernel is forbidden and the program never prints anything. From the user's point of view, the sum "never happens", since the result could not be observed.
But every modern processor executes several instructions in parallel and speculatively, that is, at risk of wasting the effort. In the example above, the CPU will probably read the kernel's byte and add 3 before discovering the read was forbidden.
Naturally, once the violation is detected, all side-effects of the offending instruction are discarded. In the example above, "b" depends on "a" which depends on the forbidden access. No variables retain their "speculated" values. But perhaps some other thing changes because of the speculation...
A silly example: if the CPU ran very hot after speculating the above instructions when "b" were odd (and therefore "a" were even), we would be able to "read" the LSB bit from all bytes of the kernel. It would take a long time, since we would have to wait the CPU to cool after each round. This "LSB bit leaking" would not be incredibly useful. But there would be trouble already, at least for crypto.
"But the program crashes, how would it read the CPU temp?" Well, we can always run another program to keep reading the temp. But it is actually easier to handle the exception within the code, so it doesn't crash. On UNIX we do this by handling or ignoring the SIGSEGV signal, and Windows has SEH. We can try forbidden things thousands of times per second without issue. We just need to find an actual "leak".
The MELTDOWN attack leaks bytes by bringing a memory page into the CPU cache. See the following pseudo-code:
char *scratchpad = malloc(256 * 4096);
... evicts scratchpad from the CPU cache ...
uint8_t *p = SOME_KERNEL_ADDRESS;
uint8_t a = *p;
uint8_t b = *(scratchpad + 4096 * a);
long long smallest_time = 9999999999999;
uint8_t leaked_a = 0;
for (int c = 0; c < 256; ++c) {
long long tsc0 = tsc();
char b = *(scratchpad + 4096 * c);
long long tsc1 = tsc();
long long tottime = tsc1 - tsc0;
if (tottime < smallest_time) {
// the smallest tottime is consequence of speculation
// made by CPU with "a" value, that brought a related
// memory page into the cache.
smallest_time = tottime;
leaked_a = c;
}
}
printf("Kernel byte %p = %02x", SOME_KERNEL_ADDRESS, leaked_a);
Instead of making "a+3", we multiply by 4096 and use the result as a pointer to read legitimate memory ("scratchpad"). As said before, all side-effects ("a" and "b") are discarded as soon as the violation is detected. But, since the speculation happens before the violation detection, a memory page was brought into the CPU cache. For example, if the byte in SOME_KERNEL_ADDRESS is equal to 23, the byte (scratchpad + 94208) will be read, and the piece of memory around it is now cached.
After that, the attacker reads all "scratchpad" bytes that could have been touched by the CPU speculation and times every reading. If the byte is in the cache, the reading costs 5 CPU cycles. If it is not, it costs 200 cycles. It is a small difference, but it can be measured with a precise clock. In particular, the x86/x64 architecture offers the TSC counter — a value that is incremented every clock cycle, and any process can read it.
Before trying to read the kernel, we need to make sure that "scratchpad" is uncached. It is easy to guarantee that. The x86/x64 architecture has a specific instruction to evict from cache (clflush) that any program can use, and there is always the brute-force approach: read out some dummy area big enough to fill up the whole cache.
Since every kernel read causes a violation that needs to be handled, and the scratch pages need to be timed, the reading rate is not that fast: preliminary tests achieved around 2000 bytes/s.
MELTDOWN is a hardware problem, a design error in the CPU. As far as we know, only a part (ok, the bigger part) of the Intel CPU lineup is affected. AMD has stated that their CPUs never speculate memory reads before checking privileges. Idem for the ARM platform. But, since it is a very new kind of attack, it would not be a complete surprise if the future brought bad news for non-Intel chips.
A very crude solution is to disable the memory cache at BIOS. This is the recommendation for MS-DOS users. Unfortunately, the performance hit is huge, around 80%.
In modern operating systems like Linux and Windows, the fix is to remove the kernel completely from the process' virtual memory. (In order to understand why the kernel was there in the first place, read the final part of this page.) This will cost some performance as well, something between 0% and 30% depending on the application.
To exploit a computer using MELTDOWN, the attacker needs to have a degree of access to the machine: upload an attack program, and run it. A non-root account, be it local or SSH, is enough.
At first sight, a Web server would be vunerable only if some user has permission to upload a CGI program. Apart from that, most "modern" network services never allow upload and/or execution of arbitrary code because this kind of feature had already been a huge attack vector in the past (e.g. the "debug" feature of Sendmail that was exploited by the Morris worm).
A big headache is the cloud. Most cloud machines are virtual, that is, they share hardware with other parties. Any hardware-level leak, even if minuscle, is a nightmare for cloud providers and users alike. As far as we know, MELTDOWN does not allow a "truly" virtual machine to steal information from the host. But most clouds are based on paravirtualization (KVM, Xen).
Consider the following pseudo-program in C, and suppose the compiler will not elide the obviously dead code:
// "a" is an integer
// "b" is a secret
if (a != a) {
// never executed (are you sure?)
c = mem[b];
} else {
c = -1;
}
If an attacker intends to find "b", a possibility is to force the reading of "mem[b]" and check which part of "mem" has been cached (much like MELTDOWN). But, if the condition for reading "mem[b]" is always false, what can we do?
Besides executing instructions in parallel and speculatively, modern processors estimate which execution path is the most likely. This estimation can be supplied by the compiler and/or it can be found at runtime by the CPU itself.
If the CPU executes the code above a handful of times, it takes note that the most likely outcome is to jump the first block; then it executes "c = -1" (and whatever comes next) speculatively, in parallel with the logical test "a != a".
One limitation of CPU-level estimation is, there must be a very simple and fast criteria to "index" the table of estimations, relating the estimation table to the conditional instructions. Things like user name, process number, etc. are too high-level. In practice, the CPU creates the "index" by mangling a handful of LSB bits of the conditional instruction's address.
As happens with any hash table, there will be a small number of clashes e.g. two different conditional instructions with "similar" address but opposing probabilities will share the same position in the estimation table, and the CPU will always mispredict one of them.
The basic idea of the SPECTRE attack is to "poison" the estimation table. The attacker program executes several times a instruction like
if (a == a) {
whose address is similar to the instruction
if (a != a) {
of the victim. When the program under attack is run again, the CPU will execute speculatively the instruction
c = mem[b];
because the CPU was convinced that the conditional would probably be true. The side effects are discarded as soon as the CPU finds that the condition is indeed false, and the victim does not crash.
But the memory page related to "mem[b]" was loaded into the cache due to the frustrated speculation. If the attacker can time the access to different parts of the "mem" array, it will find out the probable value of "b".
Before we go on, I must say that it is not easy for one program to attack another in this fashion. After all, "mem" cannot be observed from outside, not even to discover which parts are cached. Such an attack is viable when attacker and victim share some piece of memory, or better yet, share the same address space. For example, Javascript code running in a browser.
Since Javascript is often compiled into machine code by JIT interpreters, and most of the latter also implement asm.js (let's not even talk about WebAssembly), it is possible to write low-level JS code whose translation to assembly is compact and predictable, like C.
Now, consider this pseudocode that is the heart of SPECTRE attack:
var mem = SharedArrayBuffer(1);
var mem2 = SharedArrayBuffer(256 * 4096);
// evicts mem2 from cache using brute force
// choose "b" outside the 0..<b.length limit
// poisons the condition estimation below as "true"
if (b >= 0 && b < mem.length) {
c = mem2[4096 * mem[b]];
} else {
c = -1;
}
// time the access to all parts of mem2 to find out which
// part is cached, as we did in MELTDOWN
The idea of the code above is to access "forbidden" memory. This time, it is not kernel memory, it is data from the same process. It could be a Javascript program trying to escape the sandbox, or PHP code peeking into the Web server's memory. Given that a proof-of-concept SPECTRE attack was indeed written in JS, let's consider the JS-browser case for now.
If we make b=10000000, the value of mem[10000000] is outside the "mem" buffer. If it could be read, it would return a byte from the browser's memory, which is a sandbox violation. But actually trying this would crash the script. So, we protect the invalid access with an "if" condition that is always false for "interesting" values of "b".
Normally, the CPU would discover soon that our "if" is always false. But if we can convince the CPU that the "if" is probably true, the CPU will run speculatively the line
c = mem2[4096 * mem[b]];
which brings a piece of "mem2" into the cache. For example, if mem[10000000] is 30, the region around mem2[122880] would be cached. From that point on, we do as we did in MELTDOWN: time the access of different parts of "mem2". The fastest one is (probably) related to 30.
Unfortunately, SPECTRE affects most modern processors, since most of them do speculation. SPECTRE is a difficult attack to carry out, and it is probably less worrisome than MELTDOWN. On the other hand, it does not have a "simple" fix like MELTDOWN.
If you are vulnerable to MELTDOWN, you are vulnerable to SPECTRE as well. Machines with local or remote login access are the most problematic since the users can run anything using their accounts.
But the biggest issue right now is the Web browser, since it is something that everybody uses, and browsers run "hostile" Javascript code all the time. Some emergency measures have been taken: removing SharedArrayBuffer and reducing the precision of available timers, until more robust solutions are developed. I believe that all other interpreted languages and/or languages that run inside a virtual machine are affected in one way or another.
Another dangerous flank is Linux's eBPF. BPF allows the user to supply network packet filter bytecode for the kernel to run, much like a Javascript or WebAssembly program is run by the browser. Using the SPECTRE technique, a malicious BPF script could read the whole memory of the kernel with speed similar to MELTDOWN. (The eBPF bytecode is lower-level than BSD's classic BPF, so it is not clear right now whether BSD BPF is vulnerable to SPECTRE.)
Given that SPECTRE is extensible to the kernel, it might be extensible to virtual machines and to the cloud, in particular for paravirtualized machines.
As mentioned before, it is not easy to use the SPECTRE attack against an unrelated process, whom we don't share memory with. The technique laid out in the scientific article created a "synthetic victim" to demonstrate the possibility of crossing this barrier.
Attacking an unrelated process implies looking for gadgets, that is, vulnerable conditions that can be a) poisoned; b) made to access sensitive memory; c) influenced by external variables under attacker's control (e.g. environment variable, file contents, parameters, etc.).
Consider the code below, and suppose that it is legitimate, that is, it belongs to a normal program:
// a and b are external inputs, controllable by the attacker
if (...a and b are within limits...) {
c = mem2[mem[a] + b];
}
We craft "a" to access the sensitive memory mem[a] of the victim process, and we craft "b" to point to some shared library (DLL). The attack then proceeds as laid out in the previous example: poison the estimation so the CPU executes the "if" block speculatively; then time DLL pages to find out which one was cached (it will be related to "a").
As the name says, a shared library is shared among all processes that load it. The attacker loads a DLL that is also employed by the victim; this provides the crucial shared piece of memory. Of course, the same DLL may be mapped onto a different address for each process, but the attacker can use some heuristics to discover very fast where the DLL is in the victim process' address space.
One disvantage of the attack above is that "b" would have to assume really big values (positive or negative), that might be linted out by a parser or validator before reaching the "gadget". An even more insidous version of SPECTRE is based on "indirect jumps":
// a and b are external inputs, controllable by the attacker
if (...a and b are within limits...) {
x = mem[a] + b;
c = table[x]();
}
Strange as it seems, the CPU tries to execute speculatively whatever instructions are pointed by "table[x]" for any value of "x". It just needs to believe the "if" is probably true.
Knowing the internal structure of the victim program, the attacker might induce the victim to bring certain pages from DLLs into the cache using relatively small values of "a" and "b".
For now, there is no silver bullet for SPECTRE, since most general-purpose CPUs do speculative execution — and this won't change, since 80% of their performance depends on that.
So, every piece of software will need to adopt mitigatory measures. Browsers will be the focal point in the near future, as well as Linux eBPF and paravirtualization technologies like Xen and KVM.
A general solution for timesharing systems (computers where users can log in and run any kind of process), is difficult. As the attackers will find difficult to locate and exploit the so-called "gadgets". But C compiler developers are already proposing solutions to avoid the creation of indirect-jump-based gadgets.
Since quite some time, the layout of the process virtual memory is "shuffled" or randomized (ASLR). This mitigates a range of attacks like the classical buffer overflow of the 1990s. More recently, the same thing was implemented in kernel level (KASLR). The ROWHAMMER attack, that also exploits hardware defects, depends on knowing the memory layout; KASLR does not fix ROWHAMMER but renders the attack much more difficult.
Or so we thought. In the middle of 2017, the University of Graz showed that it was possible to "leak" information about kernel memory layout. By timing a (forbidden) access to kernel's memory, a process can discover whether a page is in use by the kernel. The information is not incredibly useful by itself, but it undermines the effectiveness of KASLR.
The same team predicted that more dangerous attacks could stem from the same basic tecniques, and proposed a solution: the KAISER security feature, that is simply the optional removal of the kernel from the process address space.
At first, KAISER got a lukewarm reception because it cost a performance hit; but activity around KAISER increased sharply towards the end of 2017, suggesting that the prediction was true and some dangerous attack had been discovered.
The SPECTRE attack is related to MELTDOWN, and both descend from the same initial idea.
If you are wondering why the hell the kernel can be found in the process memory (a fact that rendered possible the MELTDOWN attack), this section is for you.
In modern general-purpose operating systems (Windows, Linux, etc.) each program in execution (called process) lives inside a huge memory space, named virtual memory (VM). In a 64-bit machine, the address space of VM has 264 bytes.
Each process has its own isolated VM, and each process has the illusion of being alone in the computer. The kernel itself lives in virtual memory.
But the kernel's VM (in red, below) appears as part of the VM of each process, in the same place and with the same contents. Later I explain why.

But the virtual memory is a fiction. The physical RAM memory that you pay for is way smaller, around 234 bytes (8 gigabytes) in a typical PC. The fragments or pages of virtual memories of the processes, as well as kernel pages, are scattered in the RAM.
The mapping between real and virtual memory is carried out by CPU and kernel working together.
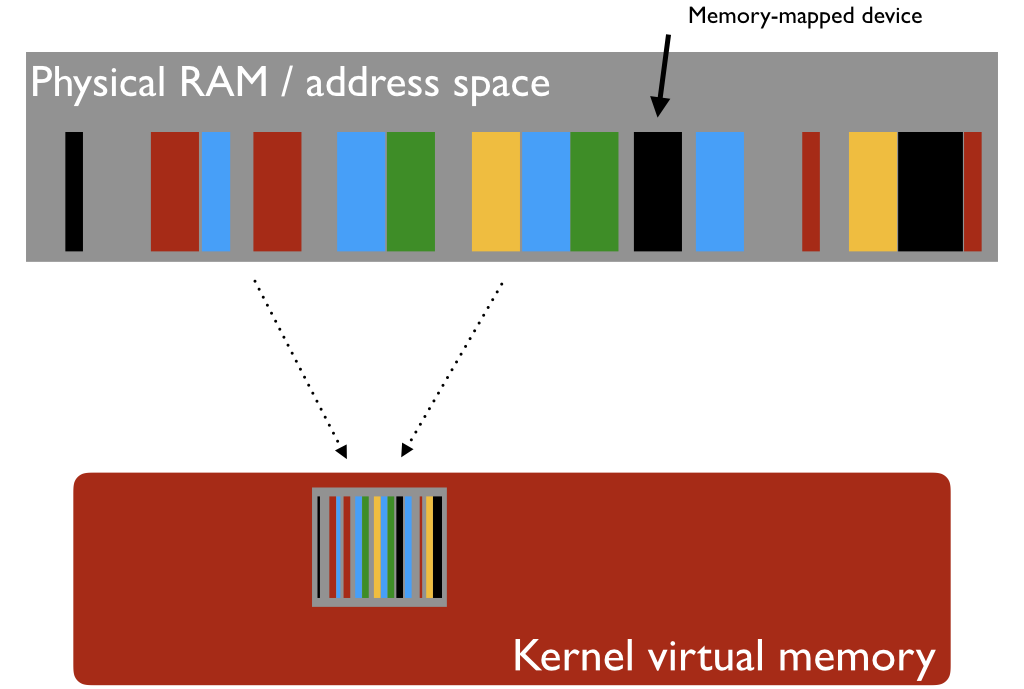
The figure above has two more items that need explanation. First: the whole physical RAM is mapped onto the kernel's virtual memory. This is possible because the RAM is much smaller.
This way, even though the kernel runs in a virtual memory context, it has direct access to the whole RAM, generally without the need of any address translation (virtual-to-real or real-to-virtual).
Another thing is the memory-mapped device. Not everything that has a physical RAM address is RAM. For example, the screen contents exist only inside the video chip, but the kernel (and authorized processes) can access these contents as if it were regular memory. (Ok, it is a bit more complicated than that because of GPUs, but you get the idea.)
So, the virtual memory of a process contains the kernel, which contains the whole RAM, which contains pieces of the process and the kernel themselves... We need an updated version of the first figure:

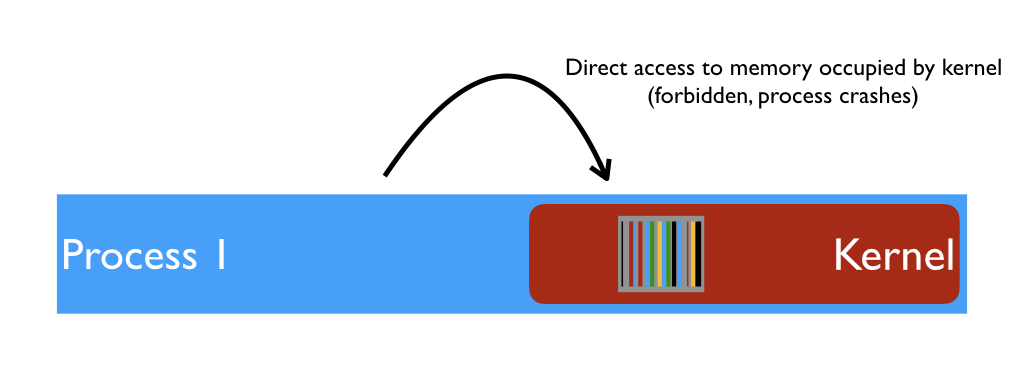
The kernel lies inside the process, but the process cannot access that part of its own memory. If it tries, an exception is raised, and typicallly this kills the process.
This security measure is guaranteed by the hardware. Each CPU architecture stipulates a number of levels or "privilege rings", and each page of memory belongs to a ring. If the CPU is running code on a Ring 3 page, that code cannot access pages of Ring 2, 1 or 0. On the other hand, code on Ring 0 pages (e.g. kernel's code) can do anything.
But there are ways to elevate the privilege. When a process makes a system call (e.g. asks to read a file from disk) the call opens the kernel VM so it can handle the call.
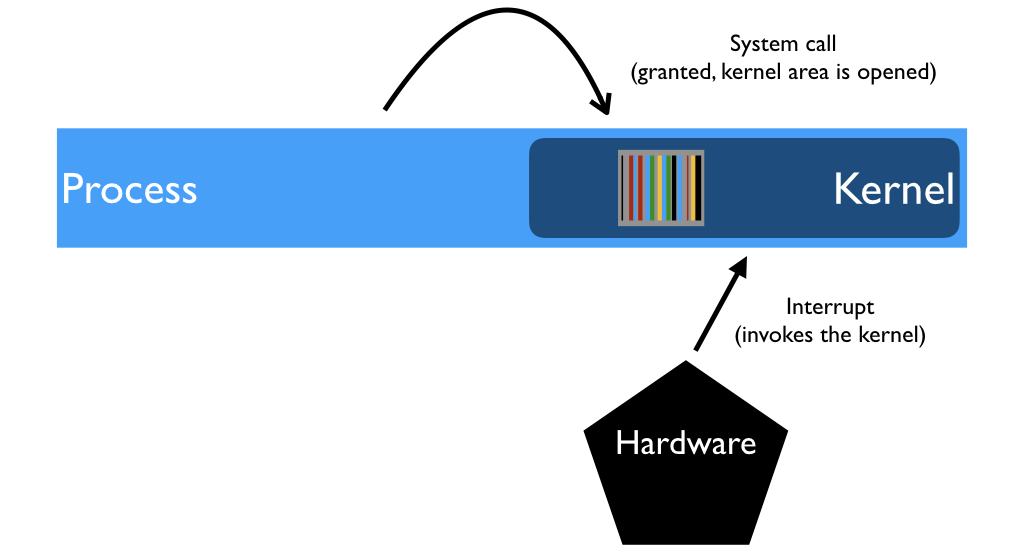
The same happens for interrupts, that is, when some hardware device needs kernel attention (e.g. the disk wants to deliver data). Whatever is the process in current execution, even if it has nothing to do with the interrupt (e.g. it didn't ask anything from disk), its VM will handle the interrupt.
In both cases (system calls and interrupts), we managed to avoid the "context switch", that is, the exchange of the current virtual memory. Switching the VM takes time, and many switches are elided when the kernel is mapped inside every process.
Unfortunately, the MELTDOWN bug enables any process to read the kernel, and therefore the whole RAM, without permission. To avoid this menace, the kernel must live in its own separate VM. In this case, every interrupt and every system call will cause two context switches, when entering and exiting the kernel.
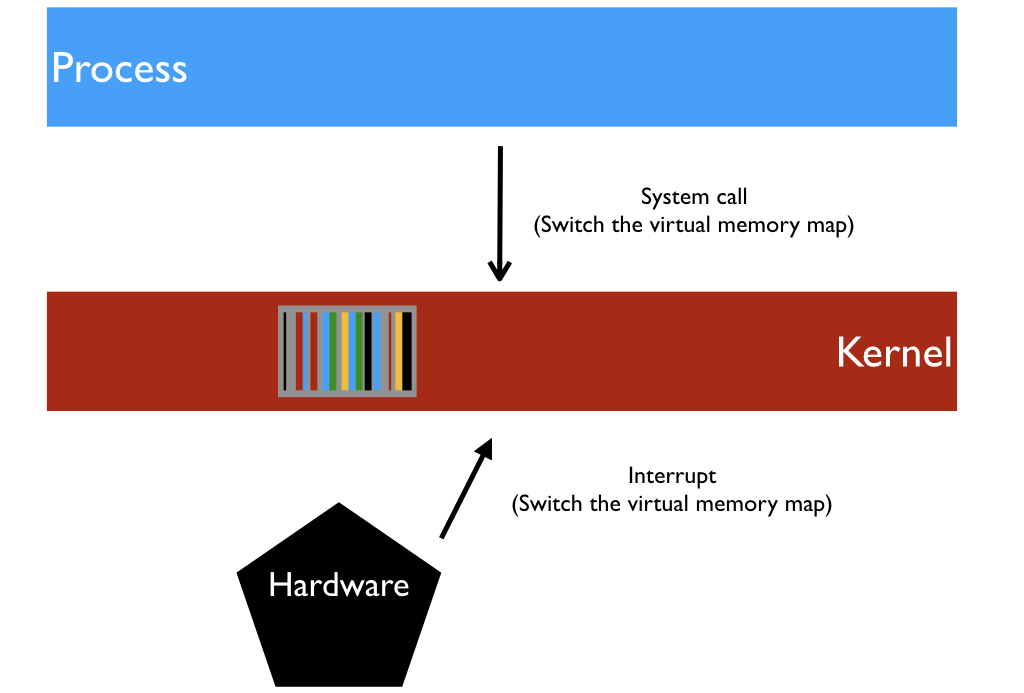
The performance hit depends on how frequently the processes call the system. Tasks like video processing, Bitcoin mining, etc. are almost unaffected, while databases (that use the disk all the time) may slow down up to 30%.