 Redes neurais 101
Redes neurais 101
Redes neurais 101
Redes neurais 101
O livro "The Brain Makers" menciona a invenção das redes neurais nos anos 1940, e as razões pelas quais elas foram escanteadas pela komunidade de pesquisadores de inteligência artificial, só para voltar a ser objeto de interesse a partir dos anos 1990, e explodir a partir dos anos 2010. Tudo que é buzzword de IA (LLM, YOLO, ChatGPT, etc.) é movido a rede neural.
Minha intenção original era incluir uma pequena introdução sobre redes neurais na resenha do livro, mas seria um jabuti, e um bem grande, então vai num texto separado.
Disclaimer: não sou um pesquisador de IA, conheço sobre o assunto apenas o suficiente para ter uma ideia de como as coisas funcionam, e me convencer que é ciência, não macumba.
Conforme o nome sugere, as redes neurais foram inspiradas em tecidos nervosos de seres vivos, observados no microscópio. Os neurônios são simples células, conectadas por axônios e sinapses.
A conclusão do pesquisador foi que um neurônio individual não pode ser muito inteligente; ele recebe sinais de outros neurônios, faz algum cálculo simples com base nos sinais de entrada, e emite um sinal de saída. Além de burro, o neurônio vivo é extremamente lento, se comparado a um componente eletrônico.
Porém, um grande número de neurônios, conectados entre si de forma intrincada por inúmeras sinapses, poderiam constituir uma calculadora mais poderosa, que de alguma forma seria capaz de implementar funções bem mais complexas. (Considerando quão capazes são os seres vivos dotados de um cérebro, a hipótese prometia.)
Além disso, como todos os neurônios trabalham em paralelo, um grande número deles poderia formar um dispositivo computacional muito rápido, apesar dos componentes individuais serem lentos.
O neurônio artificial é ainda mais simples:
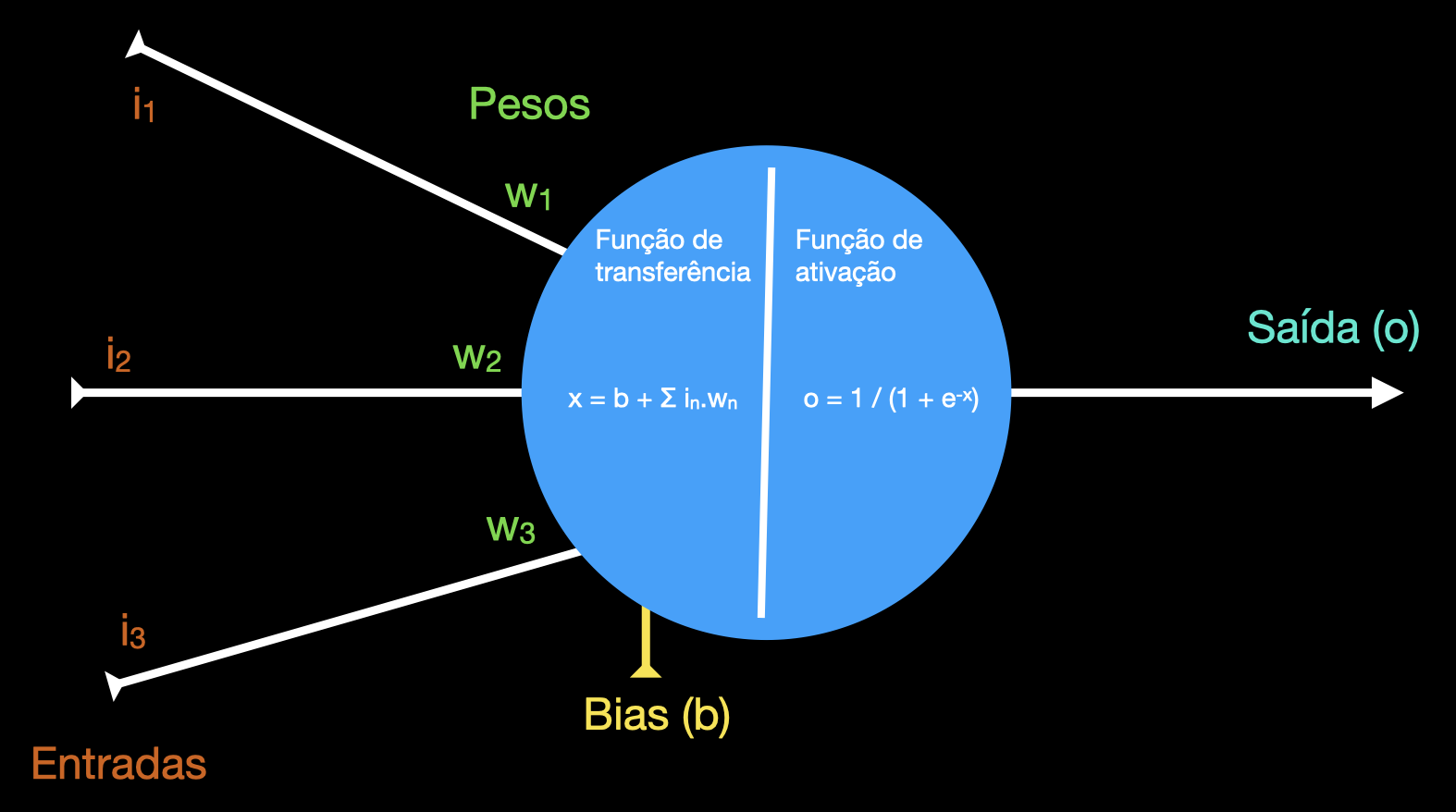
A função de transferência é apenas a combinação linear das entradas, ou seja, a soma das entradas multiplicadas por seus respectivos pesos. Mais o bias, que não depende de fatores externos.
Já a função de ativação faz com que a saída do neurônio esteja numa faixa previsível, independente da magnitude das entradas. Ela também introduz não-linearidade, que é o que permite a uma rede neural "aprender" funções mais complicadas que uma operação aritmética.
Na didática, uma função de ativação muito citada é a "curva sigmóide" ou "função logística" cuja fórmula é
𝜑(x) = 1 / (1 + e-x)
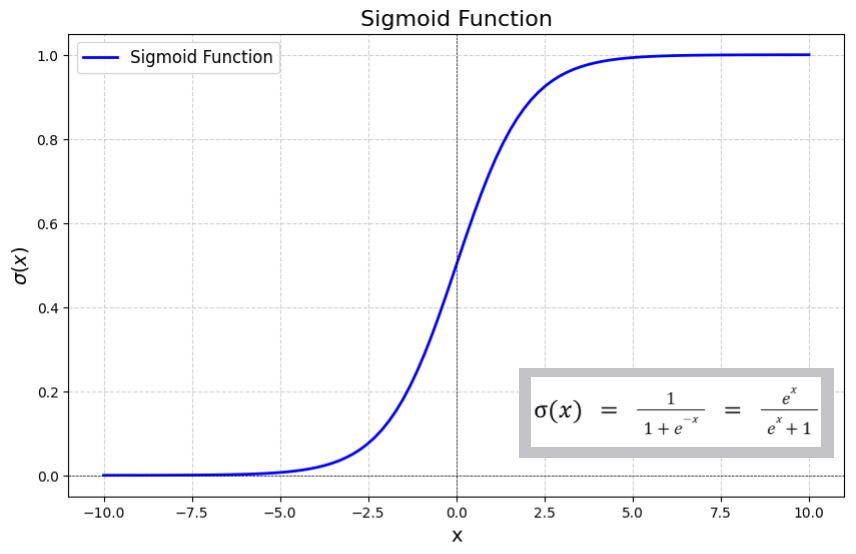
O resultado fica sempre entre 0 e 1, para qualquer valor de x. Ela tem diversas características desejáveis: é monotônica, suave, diferenciável, e sua derivada possui uma fórmula simples e recursiva:
𝜑'(x) = 𝜑(x).(1 - 𝜑(x))
Muitas outras funções são boas candidatas a função de ativação, cada uma com suas vantagens e desvantagens. Hoje em dia, utiliza-se muito alguma variação da função ReLU, que é simplesmente max(0,x), muito fácil e rápida de calcular.
A função 𝜑(x) é assintótica, ou seja, nunca atinge realmente os valores extremos 0.0 ou 1.0. Quando desejamos que a saída do neurônio seja digital, ou seja, "verdadeira" ou "falsa", precisamos adotar uma convenção razoável, e.g. considerando abaixo de 0.1 como "falso" e acima de 0.9 como "verdadeiro".
Uma vez que o neurônio artificial é implementado em software, sua função de ativação tem de ser relativamente simples. (Neurônios vivos provavelmente implementam funções muito mais variadas e complexas. Como são "hardware", isto não causa prejuízo de velocidade.)
Vamos começar com uma rede neural extremamente simples, com apenas um neurônio, uma entrada, uma saída, e função de ativação 𝜑(x):
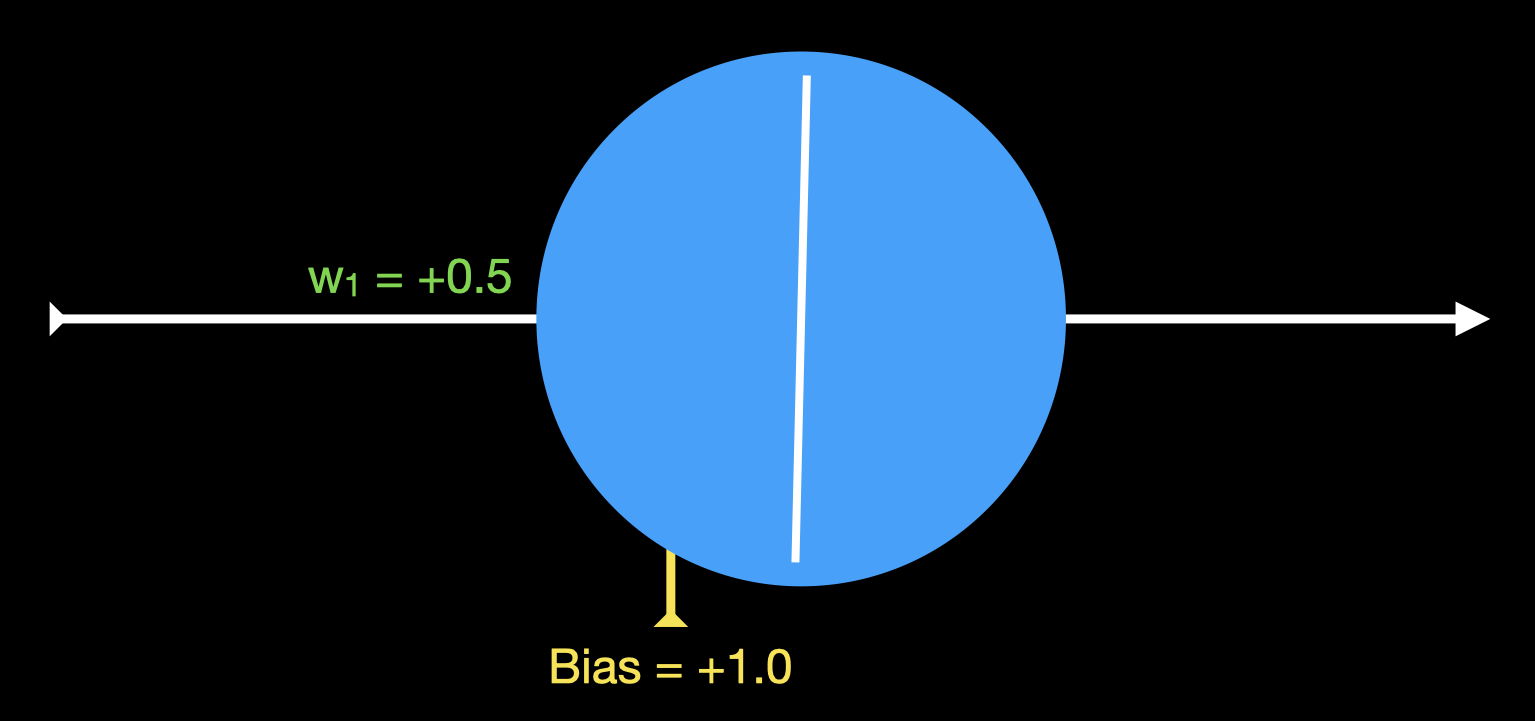
O peso inicial w1 começa igual a +0.5, enquanto o bias B começa em +1.0. Mas poderia começar com outros valores. Em geral, os pesos são iniciados com valores aleatórios pequenos.
Desejamos que esta rede "aprenda" a seguinte função que detecta números negativos menores que -10:
Agora vem a fase de treinamento da rede neural. Para isto, precisamos de um conjunto de treinamento, ou seja, amostras com valores de entrada acompanhados das saídas esperadas. Neste caso, como a função é simples e linear, o conjunto poderia ter apenas duas amostras:
O processo de treinamento consiste em
As amostras de treinamento podem ser aplicadas em seqüência ou aleatoriamente. Neste exemplo, vamos aplicá-las em seqüência. Não basta fazer isso uma vez. A cada epoch, a rede neural é exercitada novamente com as mesmas amostras.
O processo de treinamento prossegue até a rede neural demonstrar ter "aprendido" a função, o que é constatado pelo erro tendendo a zero para todas as amostras de treinamento.
Aplicando o valor da amostra A na entrada, nossa rede neural produz a seguinte saída:
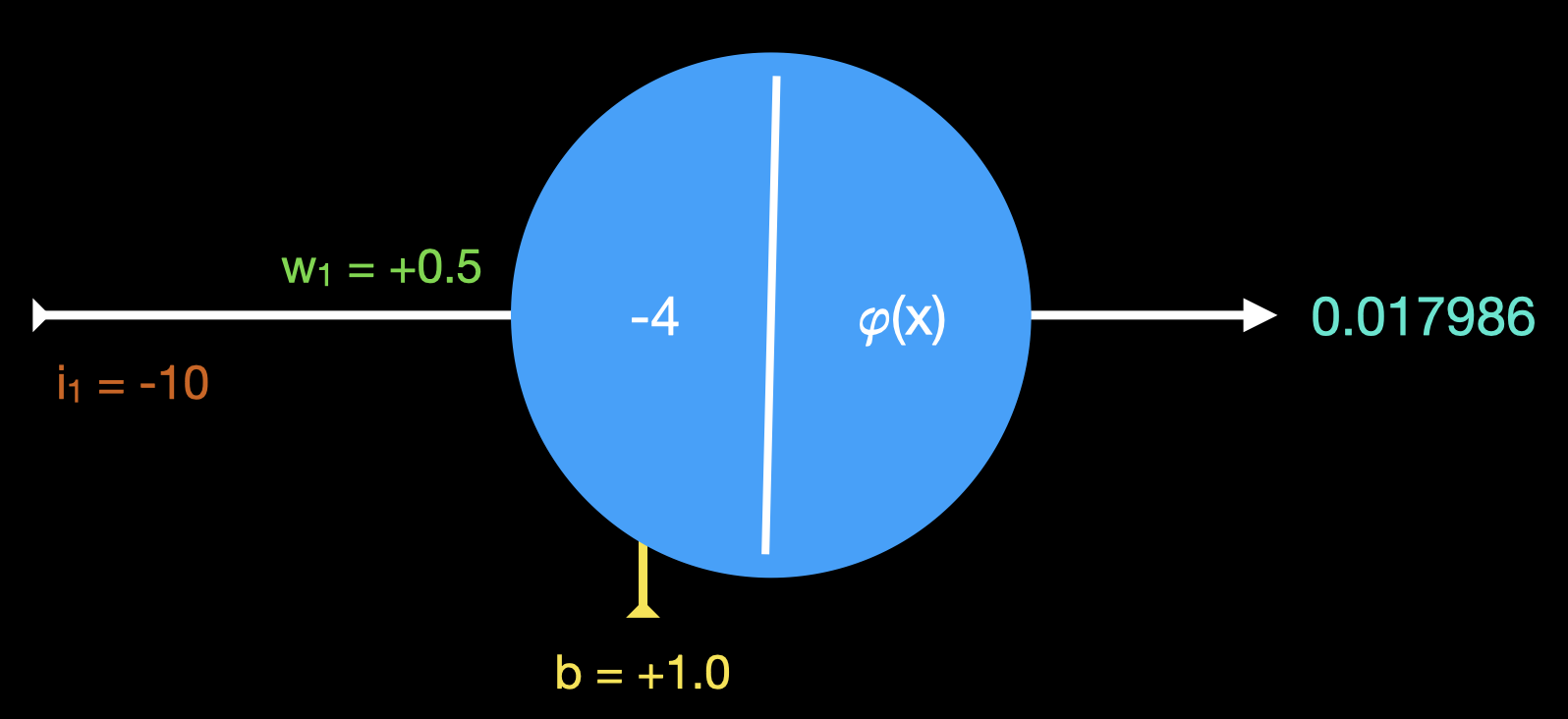
Como é a primeira rodada do primeiro exemplo, vamos fazar os cálculos um a um.
transferência = bias + (peso × entrada)
transferência = 1.0 + (0.5 × -10) = -4.0
saída = 𝜑(x) = 1 / (1 + e-x)
saida = 1 / (1 + e-(-4.0)) = 0.017986
derivada da saída ou d(saida) = 𝜑(x).(1 - 𝜑(x))
d(saida) = 0.017986 × (1 - 0.017986) = 0.017662
d(erro) = saída esperada - saída prevista
d(erro) = 0.017986 - 0.9 = -0.882014
Nesta primeira rodada, a saída possui um grande erro (-0.882014). Precisamos ajustar o peso w1 e o bias B de modo a diminuir este erro. Vamos usar as fórmulas e mais adiante discutir de onde elas vêm:
δ = d(erro) × d(saida)
δ = -0.882014 × 0.017663
δ = -0.015579
O valor δ é o erro total atribuído a um neurônio, a ser distribuído aos pesos e ao bias.
Δw1 = - η × δ × entrada
Δw1 = -1.0 × -0.015579 × -10
Δw1 = -0.155788
Δw1 é o ajuste que faremos no peso w1.
Já η é a taxa de aprendizado, que regula a magnitude do ajuste a cada rodada.
ΔB = - η × δ
ΔB = - 1.0 × -0.015579
ΔB = +0.015579
ΔB é o ajuste que faremos no bias B.
Vemos que tanto o peso quanto o bias receberam ajustes. Esta técnica de backpropagation é denominada gradient descent pois procura reduzir o erro determinando em que direção o erro "desce", e ajusta os pesos nessa direção.
Em tese, o gradient descent pode aprender qualquer função, mas isso presume ajustes infinitesimais e infinitas rodadas de treinamento. Na prática, isto significa que os ajustes nos pesos e biases devem sempre ser os menores possíveis.
Se tentarmos acelerar o aprendizado fazendo grandes ajustes por rodada, a rede nunca vai aprender. Ou vai achar uma mínima local, ou seja, vai empacar num estado em que ela "quase" aprendeu, mas não consegue melhorar além desse ponto.
Atualizando peso e bias, e aplicando a mostra B na entrada da rede neural, temos a seguinte situação:
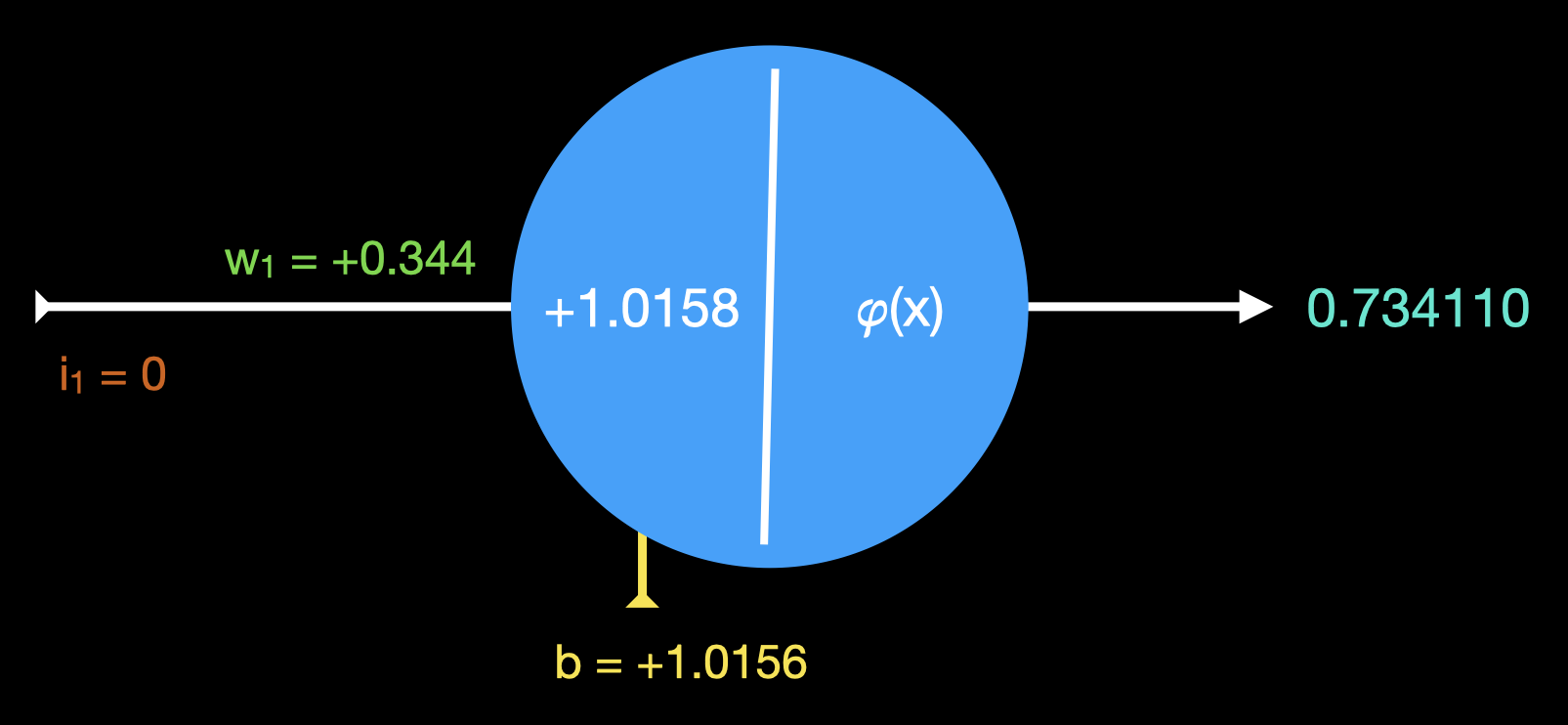
Segue abaixo a memória de cálculo desta rodada, produzida por este script Python:
rodada 1 bias 1.015579 peso 0.344212
entrada 0.000000
esperada 0.100000 saída 0.734110 erro' 0.634110
derivada saida: 0.195192
delta: 0.123773
ajuste peso: -0.000000
ajuste bias: -0.123773
Vemos que nesta rodada o ajuste de peso é zero. Isto se justifica porque a entrada do neurônio é igual a zero, portanto seja qual for o peso w1, ele não tem influência na saída, e não faz sentido ajustá-lo. Todo o erro desta rodada é "culpa" do bias, que recebeu um grande ajuste para baixo.
Tendo treinado nossa rede com todas as amostras disponíveis, fechamos um "epoch". (Nosso script conta uma rodada por amostra, então um epoch = duas rodadas.)
A cada rodada, o ajuste vai diminuindo o erro com sucesso, embora o treinamento seja bem longo:
...
rodada 10 bias 0.441433 peso -0.164474
entrada -10.000000
esperada 0.900000 saída 0.889552 erro' -0.010448
derivada saida: 0.098249
delta: -0.001027
ajuste peso: -0.010265
ajuste bias: 0.001027
...
rodada 99 bias -1.486970 peso -0.368157
entrada 0.000000
esperada 0.100000 saída 0.184377 erro' 0.084377
derivada saida: 0.150382
delta: 0.012689
ajuste peso: -0.000000
ajuste bias: -0.012689
...
rodada 327 bias -2.023769 peso -0.422061
entrada 0.000000
esperada 0.100000 saída 0.116730 erro' 0.016730
derivada saida: 0.103104
delta: 0.001725
ajuste peso: -0.000000
ajuste bias: -0.001725
rodada 328 bias -2.025494 peso -0.422061
entrada -10.000000
esperada 0.900000 saída 0.899810 erro' -0.000190
derivada saida: 0.090152
delta: -0.000017
ajuste peso: -0.000171
ajuste bias: 0.000017
Note que o gradient descent realiza uma tarefa relativamente difícil, que é ajustar duas variáveis de entrada a fim de atingir uma certa curva na saída, sem nenhuma dica além de um par de amostras.
Lembrando novamente que você pode rodar o script Python que gerou o log acima, e constatar os resultados por si mesmo.
O estado final da rede neural, depois de centenas ou até milhares de rodadas, é o seguinte:
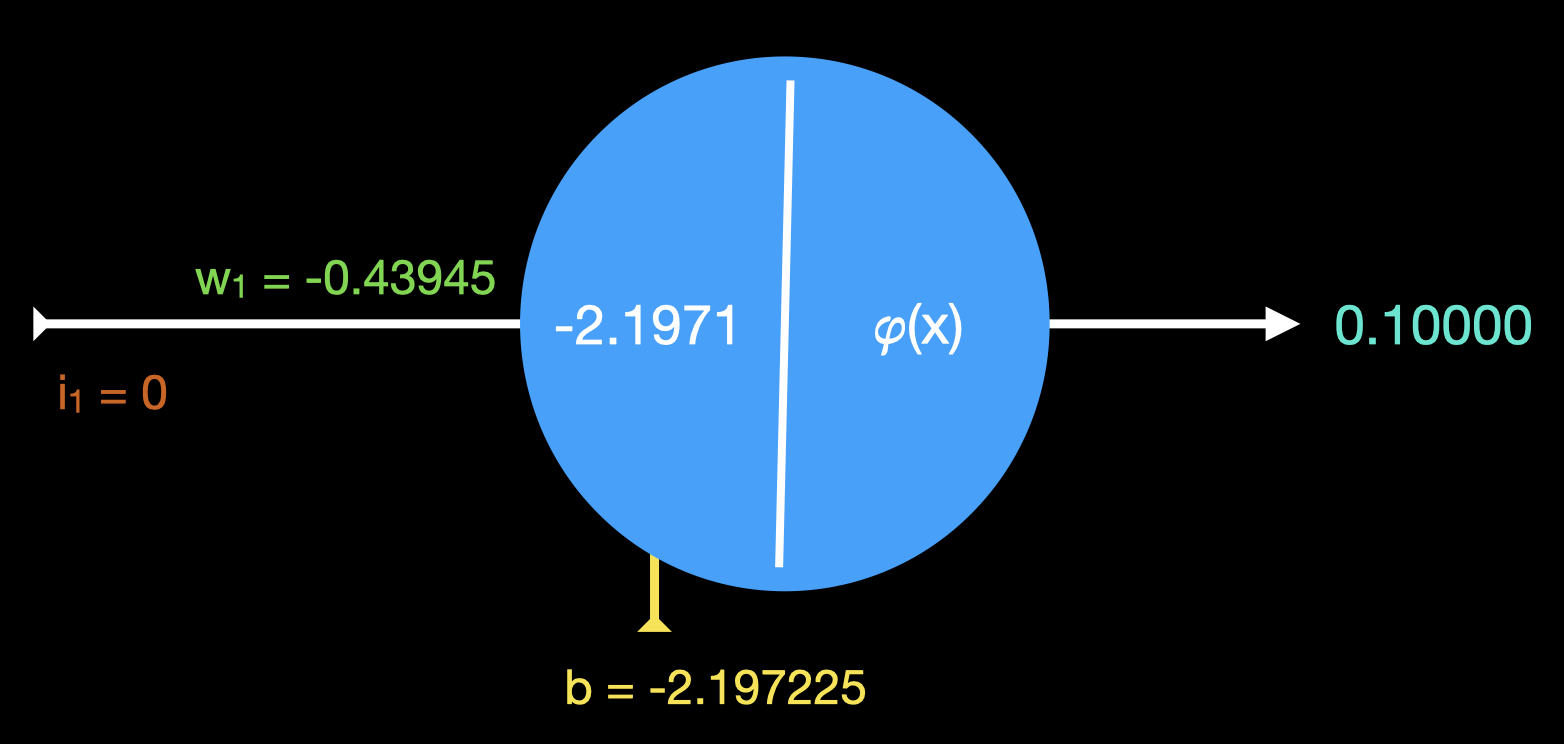
rodada 9999 bias -2.197225 peso -0.439445
entrada 0.000000
esperada 0.100000 saída 0.100000 erro' 0.000000
derivada saida: 0.090000
delta: 0.000000
ajuste peso: -0.000000
ajuste bias: -0.000000
A rede neural realmente aprende uma função a partir de amostras. Porém o treinamento é um processo custoso em recursos computacionais.
Uma vez completado o treinamento, a rede neural deve ser testada com um conjunto de conferência, ou seja, com amostras que a rede neural nunca viu antes, para confirmar que o aprendizado foi bem-sucedido, e que a rede neural é capaz de extrapolar resultados.
O estado final de uma rede já treinada, com a "memória" dos neurônios (bias e peso), mais os hiperparâmetros da rede (função de ativação, topologia da rede neural, etc.) é chamado de modelo. Alguns materiais também o chamam de hipótese.
Um modelo pode ser transplantado para outra rede neural e posto em uso imediatamente, sem treinamento adicional. Também pode ser compartilhado, comprado ou vendido, é uma propriedade intelectual por si mesmo.
As bibliotecas modernas de machine learning têm métodos para importar e exportar modelos, de forma simples e portável. Quem utiliza um YOLO da vida, provavelmente não vai treinar a rede por si mesmo; vai utilizar um modelo pronto fornecido pelo projeto, que reconhece algumas dezenas de objetos cotidianos e é suficiente para muitas aplicações amadoras.
O modelo que produzimos acima fornece respostas inequívocas para números maiores que 0 ou menores que -10. Para entradas entre -10 e 0, a saída será uma resposta "nem sim nem não", maior que 0.1 e menor que 0.9. Neste caso, isto foi de propósito.
Em muitas aplicações, uma resposta desse tipo é útil, como por exemplo um modelo treinado para reconhecer gatos. A rede pode dizer que há e.g. 60% de probabilidade de uma imagem conter um gato, o que imita o que um humano faz (nós também somos vítimas de ilusões de ótica, vemos olhos em asas de borboletas, etc.).
Se é preciso que a rede neural produza resultados realmente digitais, pode-se usar uma função de ativação digital, como o passo unitário.
Vamos revisitar as fórmulas de backpropagation por um momento:
δ = d(erro) × d(saida)
Δw1 = -η × δ × entrada
ΔB = -η × δ
Essas fórmulas têm origem na "regra da cadeia" do cálculo.
Para ajustar um peso ou um bias, primeiro precisamos saber qual o impacto que esse peso tem no erro de saída. Em particular, precisamos descobrir em que direção o ajuste deve ser feito, a fim de minimizar o erro. Para isso, precisamos calcular a derivada parcial do erro em relação ao peso.
O erro observado E(w) — erro em função do peso — é na verdade uma função composta L(A(T(entrada,w))) sendo que L() é a funcão de perda que estima o erro, A() é a função de ativação, e T() é a função de transferência, que finalmente depende do valor de entrada e do peso "w".
Por ser uma função composta, podemos calcular facilmente a derivada parcial ∂E/∂w com base nas derivadas de L(), A() e T(). Por isso era importante que a função de ativação tivesse uma derivada fácil de calcular.
A variável δ contém parte da regra da cadeia, com as derivadas de L() e A(). Já a derivada parcial ∂T/∂w é igual ao valor de entrada, por isso "entrada" aparece no cálculo de Δw1. O bias pode ser considerado como o peso de uma entrada de valor constante 1.0.
O mesmo raciocínio vale para uma rede neural multicamadas. Sempre é possível determinar a relação entre o erro da saída e o peso de uma sinapse qualquer, mesmo que ela esteja atrás de múltiplos neurônios. A única diferença é que a função composta E(w) possui mais níveis de composição, e a regra da cadeia tem de ser aplicada mais vezes.
Por último, devo esclarecer uma mentira que temos contado. Temos tratado o erro e d(erro) como se fossem a mesma coisa. Calculamos d(erro) como sendo a diferença entre a saída prevista pela rede e a saída esperada. Mas d(erro) já é a derivada da função de perda, não é a função original.
Na didática, redes neurais usam o erro quadrático como função de perda:
L(previsto, esperado) = 1/2 × (previsto - esperado)2
Esta função tem uma característica conveniente. Considerando que o valor esperado é uma constante, a derivada é
L'(previsto, esperado) = previsto - esperado
que é justamente o que temos usado como métrica de erro.
O perceptron original era algo semelhante ao nosso exemplo acima. Apenas um neurônio com inúmeras entradas, cada entrada conectada a um pixel de um sensor de imagem. O objetivo era chegar a um modelo capaz de distinguir números impressos ou manuscritos.
Infelizmente, um neurônio solitário não é capaz de executar esta tarefa. Por conta desse fracasso, as redes neurais foram desprezadas por longo tempo, até que se pôde provar que a limitação do perceptron não se aplicava a toda rede neural.
Um perceptron só é capaz de aprender funções linearmente separáveis. Informalmente, são funções onde é possível onde é possível achar uma correlação linear entre as entradas.
Se as possíveis entradas forem plotadas num gráfico bidimensional, é possível discriminá-las com apenas um corte. Num gráfico tridimensional, com apenas um plano. (O conceito continua valendo para mais de 3 dimensões, mas pode ser difícil visualizar.)
A função que ensinamos ao nosso neurônio é desse tipo, apesar de ser uma relação inversa (a saída é ativada quando o valor é negativo).
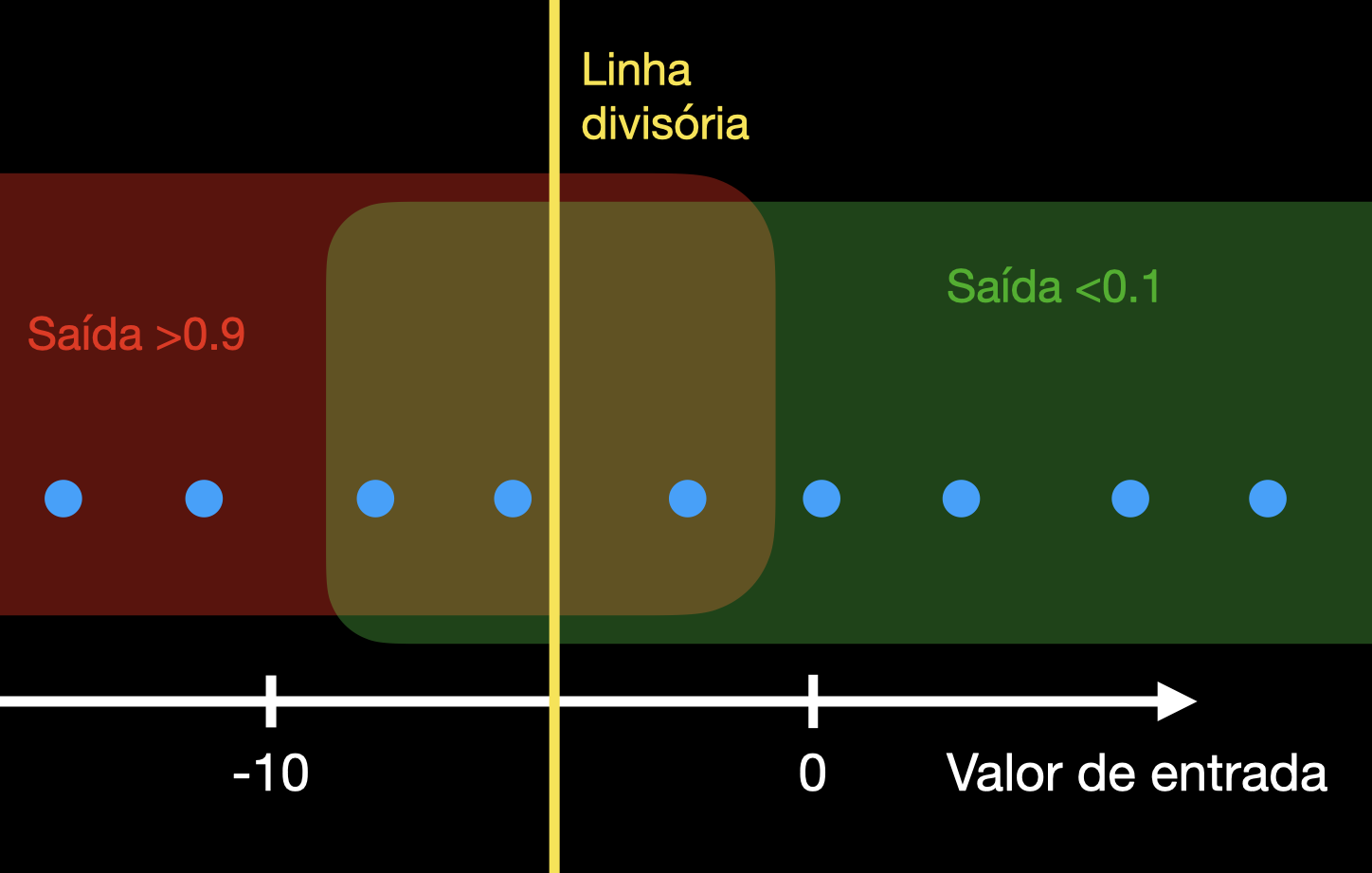
Outro exemplo de função linearmente separável é a função lógica OR, bem conhecida por quem é da profissión. A tabela-verdade para uma porta lógica OR com duas entradas é a seguinte:
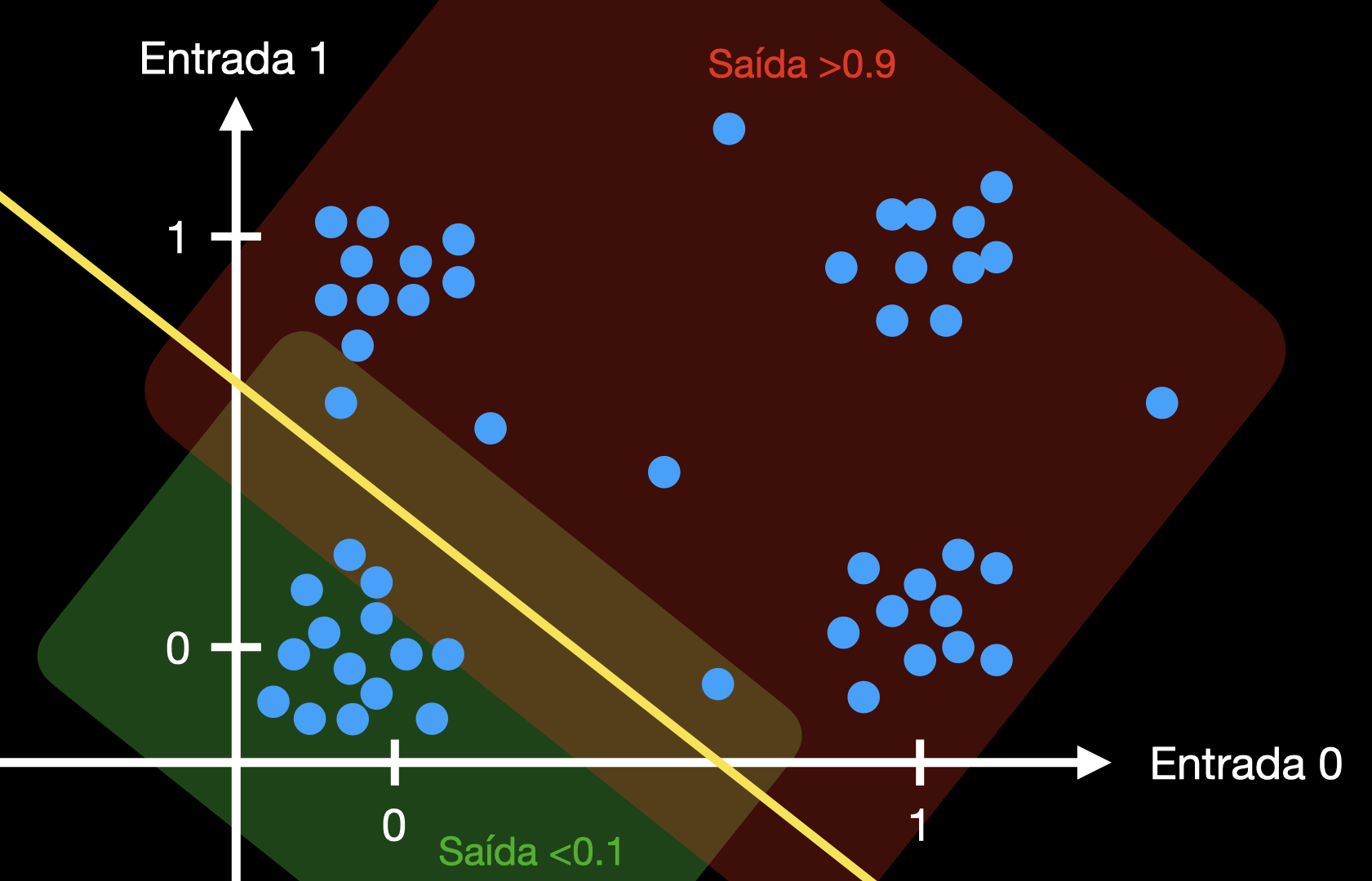
Como se pode ver acima, conseguimos separar as regiões de saída alta (>0.9) e saída baixa (<0.1) com apenas um corte. Quando as entradas são inequivocamente 0 ou 1, a saída possui valor garantidamente correto. Se as entradas possuírem valores ambíguos, em torno de 0.5, a saída também possui uma região de ambiguidade, no estilo da lógica difusa.
A função lógica XOR (eXclusive-OR) é quase igual à OR. Sua tabela-verdade para duas entradas é a seguinte:
Este é um exemplo elementar de função que não é linearmente separável. Não existe uma correlação linear válida entre as entradas e a saída. Para separar graficamente as amostras com saídas "baixas" daquelas com saídas "altas", precisamos de dois cortes.
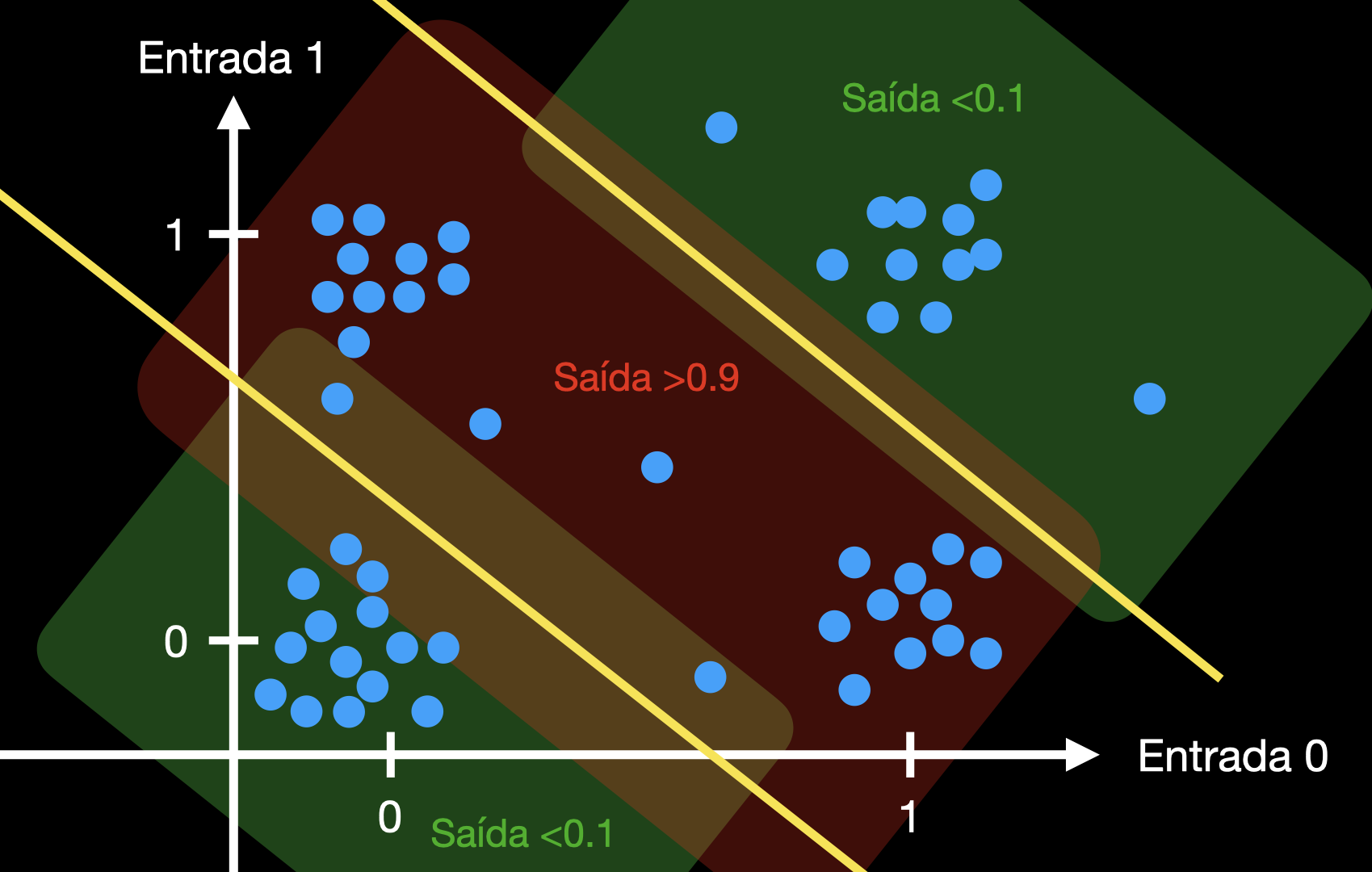
O perceptron não pode aprender a função XOR, e, como foi dito antes, isto foi falsamente usado como evidência que nenhuma rede neural poderia.
Para aprender esta função, precisamos de uma rede neural com camadas ocultas, ou seja, há mais de um neurônio entre cada entrada e cada saída. A rede a seguir é suficiente para a função XOR:
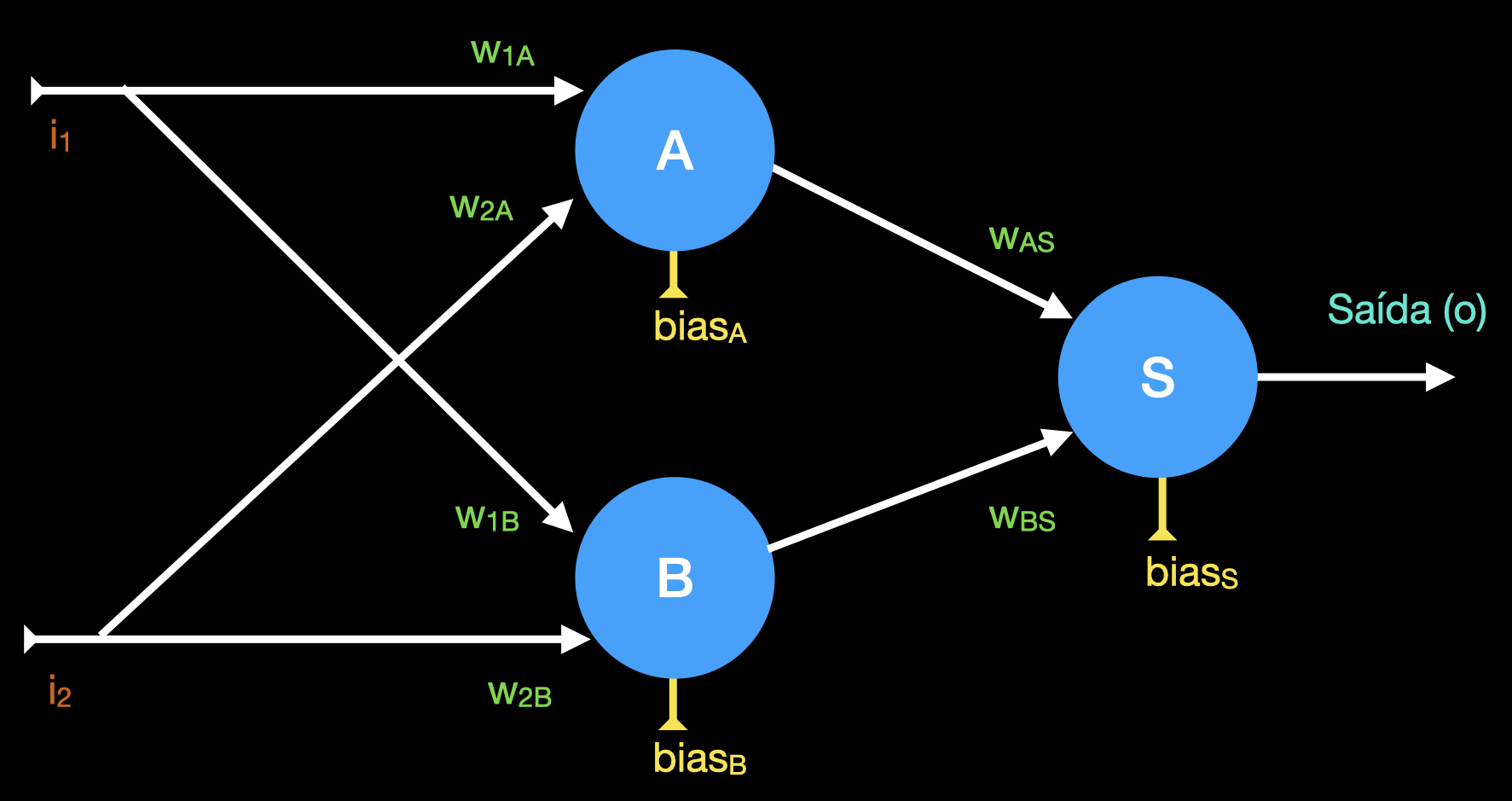
O teorema da aproximação universal prova que redes neurais com uma camada oculta podem aprender um vasto conjunto de funções, e redes com duas camadas ocultas podem aprender qualquer função.
Infelizmente, o teorema apenas prova que há uma rede neural capaz de aprender qualquer função, mas não diz como montar essa rede neural, não diz quantos neurônios são necessários, nem quanto tempo vai levar para treinar a rede.
Como vimos antes, para realizar a backpropagation e determinar o ajuste dos pesos, calculamos um valor intermediário δ, que contém o erro total de um neurônio, a ser distribuído aos seus pesos e biases:
δ = d(erro) × d(saida)
Na rede XOR, a fórmula acima ainda vale para o neurônio de saída. Porém, como agora há neurônios em camadas ocultas, precisamos de uma fórmula mais geral:
δP = Σ δQ × wP..Q × (𝜑P)'
onde
A figura a seguir procura ilustrar essa difusão de δ de frente para trás:
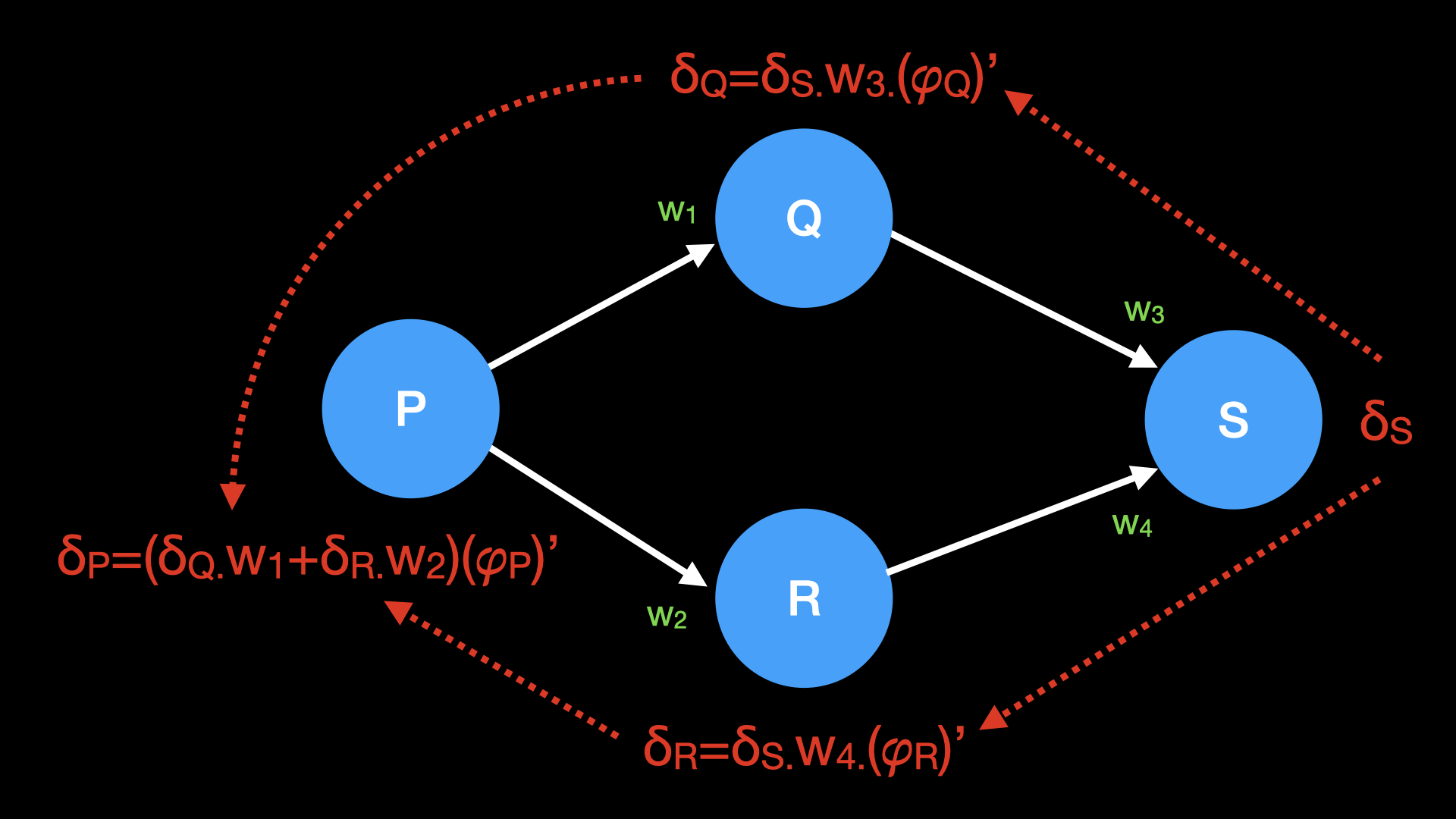
Essa definição recursiva de δ tem origem matemática na regra da cadeia, mencionada antes.
Dentro de cada neurônio, o ajuste dos pesos de entrada e do bias acontece com base em δ, exatamente do mesmo jeito que fizemos na rede de apenas um neurônio:
Δw = - η × δ × entrada
ΔB = - η × δ
Novamente, conhecer a derivada parcial da saída em relação a um peso qualquer da rede permite inferir a direção correta de cada ajuste, mas não nos permite resolver o problema em apenas uma rodada, ou mesmo em poucas rodadas. (Se fosse tão fácil, não precisaríamos de redes neurais.)
A rede neural com 3 neurônios é implementada por este script Python. Alguns comentários:
Esta versão do script utiliza pesos e biases iniciais aleatórios a cada sessão de treinamento, usando random.random(). Ela consegue aprender a função XOR em 75%-80% das execuções. Quando ela aprende, o número de epochs necessários fica mais ou menos entre 8000 e 11000.
O modelo da rede neural treinada com sucesso fica aproximadamente como a figura abaixo:
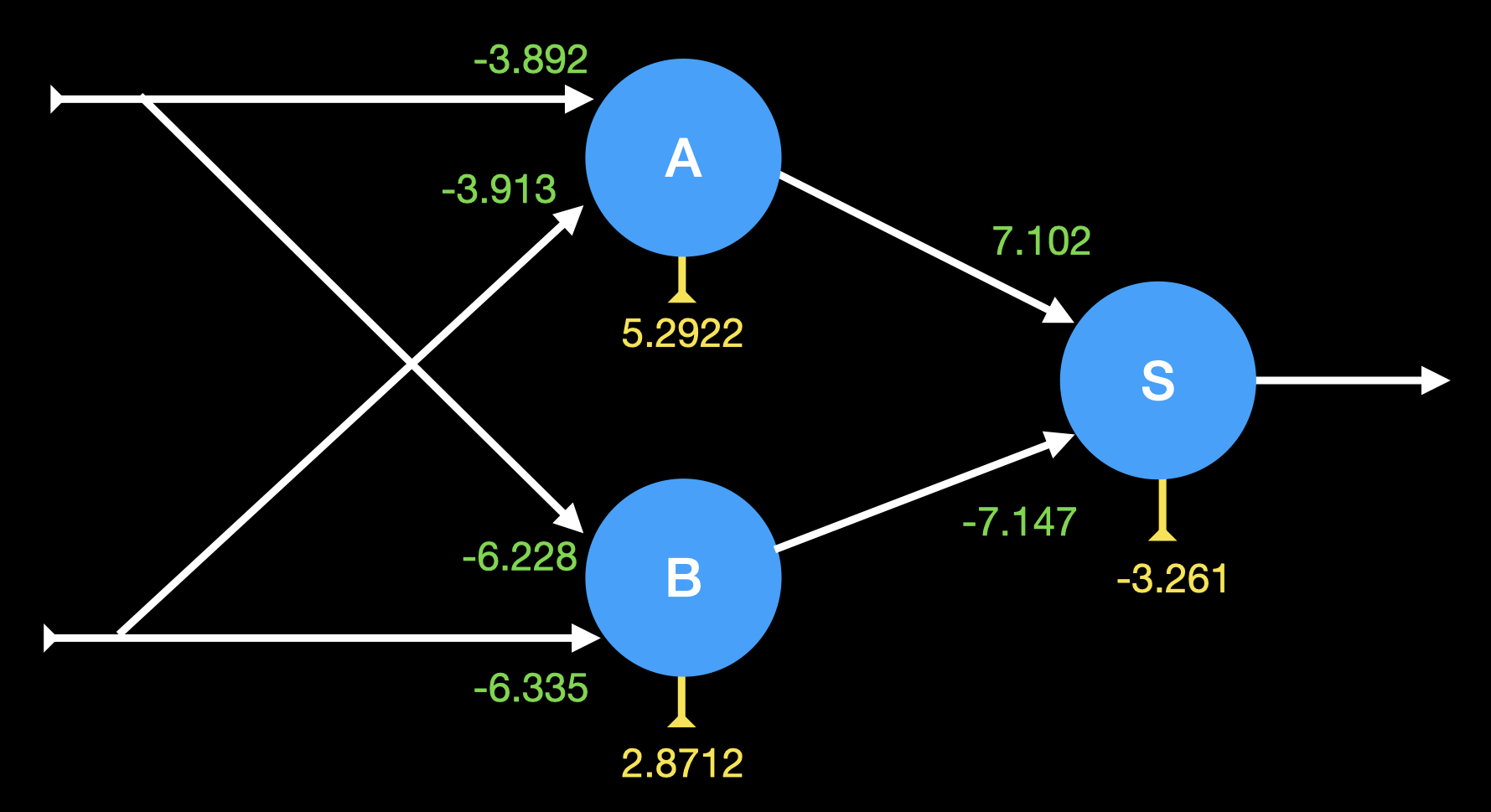
Mesmo a segunda versão do script tende a produzir modelos muito parecidos com o da figura acima. De vez em quando, ela produz modelos realmente diferentes.
Uma queixa tanto científica quanto filosófica a respeito das redes neurais é que é difícil explicar "como" elas aprendem, e qual a função de cada neurônio individual dentro do modelo. Mas, pelo menos no caso da função XOR, ainda conseguimos inferir qual a colaboração de cada neurônio:
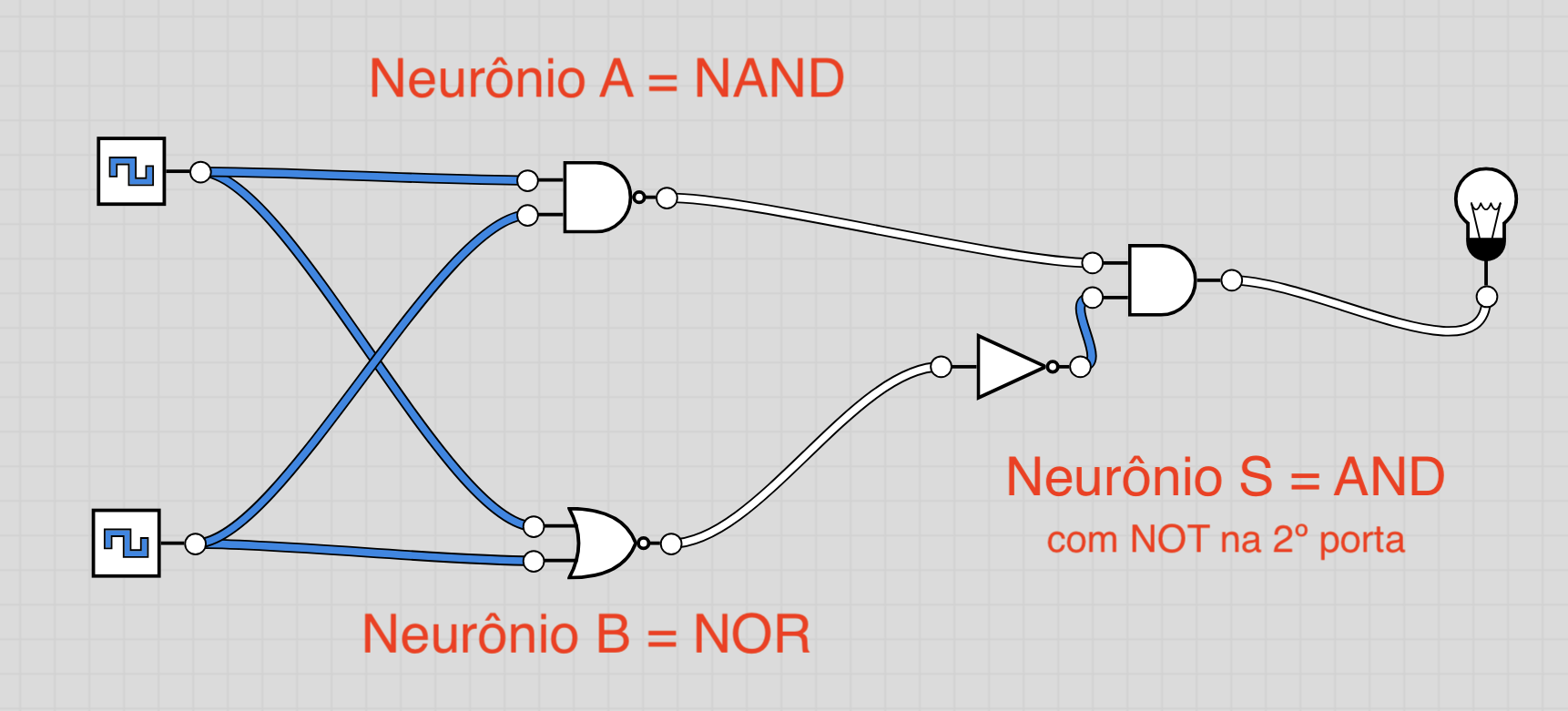
O circuito lógico acima é equivalente ao modelo da figura anterior. Os neurônios A e B implementam portas lógicas NAND e NOR. O neurônio S implementa uma porta lógica AND com um inversor na entrada vinda da porta NOR.
Sim, existe uma complexidade desnecessária nesse circuito: seria melhor usar OR em vez de NOR, o que dispensaria o NOT parasita. Mas o que você queria? São apenas 3 neurônios...
O importante aqui é entender que cada neurônio individual aprendeu uma função linearmente separável (NAND, NOR, AND), e a rede neural aprendeu a fazer a composição delas para chegar à função XOR.
Também é importante lembrar que, se os pesos e biases iniciais forem aleatórios, cada sessão de treinamento pode realizar um circuito lógico equivalente porém diferente da figura acima. Nos meus testes, observei o aparecimento esporádico de pelo menos uma variante, com portas lógicas A=AND, B=OR e S=OR, todas com inversor na segunda entrada.
Nos exemplos anteriores, implementamos as redes neurais do zero absoluto, sem usar bibliotecas de machine learning. A ideia era "sujar as mãos" mesmo, e demonstrar que os princípios de funcionamento são básicos e acessíveis.
Porém, uma vez que você se convenceu, é infinitamente melhor usar bibliotecas prontas e consagradas como o TensorFlow. Aqui estão o primeiro exemplo e a função XOR implementadas em Tensorflow. Ambos são baseadas neste tutorial.
Numa comparação direta, além do código ficar muito mais curto e mais claro, é muito mais fácil testar diferentes hiperparâmetros, diferentes estratégias de aprendizagem, etc. Não é preciso tomar conhecimento dos detalhes matemáticos.
Além do mais, como Tensorflow é utilizado por quase todo pesquisador de ML, amador ou profissional, é quase uma lingua franca da komunidade, assim como o Pandas e o R são as linguagens dos cientistas de dados.
Mas não é por usar TensorFlow que os scripts passam a fazer milagre! Para começar, são até mais lentos que os feitos "na unha". Às vezes o treinamento "empaca" na versão Tensorflow, igual acontece na versão manual, porque o problema não está no algoritmo, e sim nos hiperparâmetros, que são os mesmos em ambas as versões.
Ainda sobre o uso pervasivo de TensorFlow, é surpreendente que os modelos mais famosos sejam quase todos "open source", ou seja, os modelos "crus" (sem treinamento) das redes neurais são de amplo conhecimento público, não se faz mistério a respeito deles. Se a implementação oficial não for em TensorFlow, vai haver uma implementação alternativa em TensorFlow para fins didáticos.
Uma rede neural pode aprender qualquer função, porém redes neurais só podem lidar com números, não com símbolos. Até podemos imaginar como uma rede neural poderia interpretar uma imagem, cada pixel sendo interpretado como um valor numérico, como o Perceptron fazia.
E quanto a vídeos, sons, palavras, linguagem natural? Bem, esta é a fronteira atual da pesquisa em IA — fazer esta conversão de mídias diversas para números que possam ser processados (de forma eficiente) por uma rede neural:
Bem mais acima, citamos a função ReLU como uma função de ativação eficiente e muito popular. Ela é conceitualmente igual a um detector de envelope, utilizado em receptores de rádio AM. Alguns materiais inclusive chamam-na de "função detectora". Isso autoriza pensar que a rede neural é, num certo sentido, um demodulador de sinal.
Em geral, uma função de ativação tem de ser não-linear. Isso tem outro paralelo com rádio: no processo de modulação ou demodulação AM, o "coração" do processo é modulador. O ideal é o modulador balanceado, caro e difícil de construir. Mas qualquer componente não-linear pode atuar como modulador, desde que os subprodutos indesejados sejam removidos por filtragem. É mais um paralelo entre rede neural, rádio e DSP.
A implementação FFT da transformada de Fourier opera de forma semelhante a um banco de moduladores em paralelo e em cascata, e sua estrutura interna é muito semelhante a uma rede neural. Este texto afirma mesmo que a transformada de Fourier "é" uma rede neural, e inclusive "ensina" uma rede neural a calcular FFT.
Esse parentesco não é por acaso. A rede neural é um algoritmo de detecção de correlações. É a ferramenta mais avançada dentre outras com o mesmo fim: correlação, autocorrelação, convolução, modulação, análise espectral, todas elas utilizadas em DSP e estatística.
Este artigo me inspirou a escrever este texto.
Este canal do YouTube, cujo autor é brasileiro, é bastante didático. Em particular os vídeos sobre backpropagation são muito bons e divertidos.