 Algoritmos de ordenação (sort)
Algoritmos de ordenação (sort)
Algoritmos de ordenação (sort)
Algoritmos de ordenação (sort)
Num curso de programação avançada ou ciência da computação, ensina-se sobre algoritmos. Dentre eles, os algoritmos de ordenação ou sort costumam ser os primeiros a serem abordados, pois são fundamentais e porque podem ser facilmente relacionados com atividades humanas corriqueiras, por exemplo ordenar um baralho de cartas.
Qualquer um sabe ordenar um baralho, e nem precisa pensar muito para fazer isso. Mais difícil é descrever com exatidão cada passo elementar do processo. O principal talento de um bom desenvolvedor é fazer justamente isso: descrever uma tarefa grande em inúmeros passos pequenos, pois só assim o computador "entende" o que fazer.
Colocar um algoritmo para funcionar tem duas fases: a inspiração e a transpiração. Inspiração é o "pulo do gato", a grande sacada, a parte inovadora. Transpiração é garantir que o algoritmo vá funcionar em todos os casos fortuitos.
Ordenação é um problema do tipo NP: existe forma "rápida" de verificar se uma lista (ou vetor, ou matriz, ou baralho, chame como quiser) está em ordem. Basta olhar se cada elemento é menor ou igual ao próximo. Também é um problema de tipo P, pois existe algoritmo "rápido" (na verdade, polinominal) capaz de ordenar uma lista.
Para começar cedo a transpiração, vejamos a implementação em Python do algoritmo que verifica se uma lista está em ordem:
lista = [4, 7, 3, 8, 6, 1, 2, 5]
def em_ordem():
i = 0
while i < len(lista) - 1:
if lista[i] > lista[i + 1]:
return False
i += 1
return True
print(em_ordem())
Nesta tarefa tão simples, já tivemos de lidar com muitos detalhes de implementação: o valor de "i" começa em 0 porque, em Python, o primeiro item de uma lista tem índice zero. O valor de "i" só vai até o penúltimo item (índice 6) pois a comparação se encarrega de pareá-lo com o próximo (e último) item.
Se você já conhece programação, deve estar achando o exemplo acima bem bobo. Mas, num algoritmo mais elaborado, é esse tipo de detalhe que faz suar. Provar que uma implementação funciona em todos os casos possíveis não é nada fácil. (Muitos desenvolvedores profissionais não dominam sequer o conceito de lista ou vetor, então chegar numa versão correta do algoritmo acima, e entender por que ela é correta, já seria uma grande conquista para muita gente!)
O algoritmo acima é O(n) ou linear; sua complexidade — ou seja, o trabalho que ele tem de fazer para chegar no resultado — é linearmente proporcional ao tamanho da lista. Este é o preço de saber se uma lista está em ordem, não há como fazer melhor.
Em se tratando de sort, ouve-se muito falar que "Bubble Sort é o pior algoritmo" (não é), que Bubble Sort é inútil (não é) e que Bubble Sort tem complexidade exponencial (não tem). Para provar isso, vou mostrar apenas dois algoritmos bem piores que Bubble Sort.
O primeiro é o Bogo Sort. Pegue um baralho de cartas, embaralhe, e ponha as cartas na mesa. Se não estiver em ordem, embaralhe de novo. Simples, não? Uma possível implementação em Python:
while not em_ordem():
random.shuffle(lista)
Uma lista com apenas 8 elementos pode ser embaralhada de 8!=40320 formas diferentes. Na média, o algoritmo acima vai fazer umas 20 mil tentativas até chegar numa lista ordenada. A complexidade do algoritmo é fatorial – O(n!). Apesar disso, ele é O(1) no melhor caso: se a lista estiver em ordem, ele termina em apenas 1 ciclo.
Se o algoritmo acima fosse o único possível, ninguém jogaria cartas, porque seria infinitamente demorado ordenar um baralho, ou mesmo uma mão de cartas. Então, é óbvio que há algoritmos melhores. Porém, existem problemas NP cuja única solução é parecida com esta acima: ficar tentando combinações aleatórias até achar a solução.
Uma variante "eficiente" do Bogo Sort é o Bozo Sort: em vez de embaralhar, apenas troca duas cartas aleatórias de lugar. Em Python:
while not em_ordem():
i = random.randint(0, len(lista) - 1)
j = random.randint(0, len(lista) - 1)
lista[i], lista[j] = lista[j], lista[i]
Apesar de economizar o esforço do embaralhamento, a complexidade do Bozo Sort ainda é O(n!). Complexidade fatorial é considerada pior que exponencial O(2n). Mas tanto os problemas exponenciais quanto fatoriais são considerados "intratáveis".
Perto do Bozo Sort, o Bubble Sort é quase uma obra-prima! A ideia básica do Bubble Sort é varrer a lista e permutar itens adjacentes fora de ordem. Quando uma varredura não fizer mais nenhuma permutação, é porque a lista está em ordem.
Implementação em Python:
sujo = True
while sujo:
sujo = False
i = 0
while i < len(lista) - 1:
if lista[i] > lista[i + 1]:
lista[i], lista[i + 1] = \
lista[i + 1], lista[i]
sujo = True
i += 1
Se você fizer um teste de mesa do Bubble Sort, vai notar logo que a carta mais alta vai para seu lugar de direito logo no primeiro ciclo, a segunda mais alta no segundo ciclo, etc. A rotina acima pode ser otimizada para não comparar os itens finais, já ordenados:
j = len(lista)
sujo = True
while sujo:
sujo = False
i = 0
j -= 1
while i < j:
if lista[i] > lista[i + 1]:
lista[i], lista[i + 1] = \
lista[i + 1], lista[i]
sujo = True
i += 1
A complexidade do Bubble Sort é quadrática O(n2), não exponencial como às vezes se lê por aí. Ainda é ruim, mas é tolerável para uma lista curta. É um algoritmo muito simples de entender, e é fácil de implementar corretamente.
Existe uso prático para Bubble Sort? Hoje em dia, a chance de um programador se ver obrigado a implementar sort é quase nula, seja qual for o algoritmo, pois toda plataforma oferece uma ou mais funções de sort prontas para uso. Resta o valor didático, e talvez este conhecimento seja cobrado naquelas famigeradas entrevistas técnicas.
Eu mesmo usei Bubble Sort uma ou duas vezes na vida, para ordenar listas curtas, com meia dúzia de itens, em plataformas muito pobres de recursos, numa época em que não havia Internet para buscar um exemplo pronto. Preferi implementar o Bubble Sort (que funcionou de primeira) do que perder tempo buscando documentação.
Pedi para meu filho pequeno ordenar cartas de baralho. Depois, pedi para ele descrever exatamente como ele fazia, e a explicação saiu algo parecida com o algoritmo por seleção.
A ideia básica é selecionar o elemento de menor valor e movê-lo para o começo da lista. Vá repetindo o processo com o resto da lista, até não sobrar nada.
Implementação em Python:
i = 0
while i < len(lista) - 1:
j = i + 1
while j < len(lista):
if lista[i] > lista[j]:
lista[i], lista[j] = lista[j], lista[i]
j += 1
i += 1
Este algoritmo compartilha muitas características com o Bubble Sort: tem complexidade quadrática, é simples de entender e fácil de implementar corretamente. Ele é pior que o Bubble Sort ao trabalhar listas quase ordenadas, pois não detecta precocemente que o trabalho terminou.
A ordenação por inserção possui o embrião de uma grande ideia: começar com uma parte pequena da lista, que já está ordenada, e ir absorvendo o resto.
No início, ele considera os dois primeiros elementos, permutando-os se necessário. A seguir, o terceiro elemento é considerado, e inserido no lugar correto em relação aos outros dois. E assim por diante.
A ideia ainda é simples, mas a implementação já começa a exigir mais "transpiração". Embora o código abaixo pareça simples, já dá um certo trabalho garantir que os índices não vão sair dos limites da lista, e que a implementação é correta. (E sim, eu reimplementei na mão cada algoritmo no processo de escrita deste texto, para sentir a dificuldade.)
i = 1
while i < len(lista):
valor = lista[i]
pos = i - 1
while lista[pos] > valor and pos >= 0:
lista[pos + 1] = lista[pos]
pos -= 1
lista[pos + 1] = valor
i += 1
A implementação acima faz duas coisas ao mesmo tempo: procura pela posição correta de "valor", e vai empurrando os elementos maiores uma casinha para a direita, abrindo espaço para inserir "valor" no seu lugar de direito. Uma implementação mais ingênua poderia primeiro achar a posição, e só depois abrir espaço. Seria um pouquinho menos eficiente, mas seria mais fácil de acertar de primeira.
O insertion sort (e às vezes o selection sort) tem um nicho de uso: ordenação de listas muito pequenas, onde a definição de "pequena" varia de 4 a 20 elementos. Ele pode ser empregado diretamente, ou como auxiliar dos algoritmos mais avançados merge sort e Quicksort.
Por ser mais "cabeludinho", este algoritmo não seria minha primeira escolha naquela situação descrita antes, ainda ficaria com bubble sort ou selection sort. Mas é importante entender bem o insertion sort, pois ele é base do Shell Sort.
A ordenação por inserção ainda tem complexidade quadrática no pior caso, porém é muito rápida quando a lista está quase ordenada, apresentando complexidade linear quando faltam apenas algumas permutações de itens adjacentes para terminar o serviço. Esta virtude é explorada no Shell Sort.
O Shell Sort é parecido com a ordenação por inserção, porém ele começa comparando elementos distantes, e vai diminuindo a distância paulatinamente. Na última passagem, a distância é unitária e o processo é idêntico ao insertion sort.
Na minha opinião é o algoritmo de sort mais difícil de entender. É difícil entender como ele funciona; é difícil lembrar como ele funciona sem olhar documentação; não é óbvio que ele sequer funcione; e não é óbvio por que ele seria mais eficiente.
gaps = [ 3, 2, 1 ]
for gap in gaps:
i = gap
while i < len(lista):
valor = lista[i]
pos = i - gap
while lista[pos] > valor and pos >= 0:
lista[pos + gap] = lista[pos]
pos -= gap
lista[pos + gap] = valor
i += 1
Note que o ciclo interno da implementação acima é idêntico ao algoritmo de inserção, e tem de ser, pois ele degrada para inserção quando gap=1. A seqüência de gaps pode conter quaisquer números, só é obrigatório que termine em 1.
A complexidade máxima teórica do Shell Sort não é conhecida com exatidão; estima-se algo em torno de O(n1.25). A complexidade típica tem expoente em torno de 1.5, mas pode degradar para quadrática se a seqüência de gaps for azarada.
A melhor seqüência de gaps ainda é objeto de estudo. Uma seqüência simples e suficientemente boa é [..., 17, 9, 5, 3, 2, 1] (potências de 2 mais 1). Naturalmente, deve-se começar por um gap menor que o tamanho da lista a ser ordenada.
O Shell Sort faz um ordenamento rápido e grosseiro nas primeiras passagens. Como vimos antes, o insertion sort torna-se rápido quando a lista está parcialmente ordenada. Este é o segredo do sucesso. As primeiras passagens têm complexidade subquadrática por conta do "gap" grande, e as passagens seguintes têm complexidade subquadrática porque trabalham dados parcialmente ordenados.
Apesar de interessante, o Shell Sort é praticamente obsoleto. Ele ainda encontra uso em computação embarcada, em kernels, etc. pelo fato de sua implementação ser muito "leve" e apresentar performance suficiente para listas de tamanho moderado.
O algoritmo Quicksort baseia-se na velha máxima da guerra: "dividir para conquistar".
Escolhe-se um valor, denominado "pivô", para dividir a lista em duas partes. Os elementos maiores que o pivô são transferidos para a segunda parte, os menores para a primeira parte. Repete-se o procedimento com cada parte, recursivamente.
O Quicksort tem complexidade O(n log n) e é considerado o melhor algoritmo de uso geral. Porém, realizar essa performance depende de escolher bem o pivô. O ideal seria que ele dividisse a lista em duas metades iguais. Na prática, escolher um pivô aleatório é geralmente suficiente.
Na hora da implementação, a parte mais chata do Quicksort é transferir os elementos que estão do lado errado do pivô. Uma forma fácil seria copiar os elementos para listas novas. Mas isto gasta memória extra, e a grande virtude do Quicksort é justamente permitir a ordenação "in place", ou seja, sem usar memória extra além da própria lista. Se podemos ser pródigos com a memória, é melhor usar o merge sort, mais simples de implementar.
A implementação a seguir executa o Quicksort "in place", e usa uma técnica algo ineficiente, porém segura: contar o número de elementos menores que o pivô antes de transferi-los.
def qsort(lista, inicio, fim):
if (fim - inicio) <= 1:
return
# Escolhe pivô
pivo = lista[random.randint(inicio, fim - 1)]
# Conta elementos que devem ficar à esquerda do pivô
menores = 0
iguais = 0
i = inicio
while i < fim:
if lista[i] < pivo:
menores += 1
elif lista[i] == pivo:
iguais += 1
i += 1
# Caso fortuito: todos os elementos são iguais ao pivô
# (provocaria recursão infinita)
if iguais == (fim - inicio):
return
# Transfere elementos que estão do lado errado
i = inicio
imax = j = inicio + menores
while i < imax and j < fim:
if lista[i] < pivo:
i += 1
elif lista[j] >= pivo:
j += 1
else:
lista[i], lista[j] = lista[j], lista[i]
i += 1
j += 1
# trabalha cada semi-lista
qsort(lista, inicio, inicio + menores)
qsort(lista, inicio + menores, fim)
qsort(lista, 0, len(lista))
print(lista)
Mesmo contando os elementos, a implementação já fica bastante envolvente. Não é o tipo de coisa que se deva fazer no dia-a-dia, porque é difícil provar que todos os casos fortuitos foram tratados.
A forma eficiente de transferir elementos para antes ou depois do pivô é usando dois apontadores, um varrendo do começo para frente, e outro do final para trás, até que eles se cruzem:
def qsort(lista, inicio, fim):
if (fim - inicio) <= 1:
return
# Escolhe pivo
pivo = lista[random.randint(inicio, fim - 1)]
# Acha os limites das listas 'antes' e 'depois' do pivô:
i = inicio
j = fim - 1
while i <= j:
# Acha elemento fora do lugar à esquerda
while lista[i] < pivo:
i += 1
# Acha elemento fora do lugar à direita
while lista[j] > pivo:
j -= 1
# Troca
if i <= j:
lista[i], lista[j] = lista[j], lista[i]
i += 1
j -= 1
# trabalha cada semi-lista
qsort(lista, inicio, j + 1)
qsort(lista, i, fim)
qsort(lista, 0, len(lista))
print(lista)
O código acima pode parecer simples, e até pode parecer ineficiente ou "errado" pois ele faz trocas aparentemente desnecessárias, quando lista[i] e lista[j] são ambos iguais ao pivô. Porém, as aparências enganam: ele tem diversos refinamentos ocultos. Por exemplo, ele não engasga quando todos os elementos forem iguais.
Finalmente, a implementação pode ser otimizada em outros aspectos. Provavelmente é mais rápido delegar a ordenação de sub-listas muito pequenas, e.g. 4 elementos ou menos, para o insertion sort.
O merge sort também usa a estratégia de "dividir para conquistar", mas troca a elegância do Quicksort por um pouco de força bruta.
A mecânica básica é dividir a lista em metades iguais, ordená-las, e depois mesclá-las de novo, de forma ordenada. O processo é repetido recursivamente.
Implementação em Python:
def mergesort(lista):
if len(lista) <= 1:
return lista
h = len(lista) // 2
# Ordena cada metade
a = mergesort(lista[0:h])
b = mergesort(lista[h:])
# Mescla as metades em ordem
i = 0
j = 0
nova = []
while i < len(a) and j < len(b):
if a[i] < b[j]:
nova.append(a[i])
i += 1
else:
nova.append(b[j])
j += 1
while i < len(a):
nova.append(a[i])
i += 1
while j < len(b):
nova.append(b[j])
j += 1
return nova
print(mergesort(lista))
Comparado ao Quicksort, o merge sort é muito tranquilo de implementar. Além disso, ele não tem condicionantes de desempenho, como o Quicksort e seu pivô, ou o Shell sort e seus gaps. Ele simplesmente funciona, sempre com bom desempenho.
A única grande desvantagem do merge sort é exigir memória extra para gerar a nova lista mesclada, da ordem de O(n), ou seja, proporcional ao tamanho da lista. É um algoritmo amplamente utilizado, assim como o Quicksort.
Diferente dos outros dois, o heap sort não é adepto de "dividir para conquistar". A complexidade da ordenação é diminuída pelo uso de um heap ou árvore binária. Árvores são estruturas que permitem localizar dados rapidamente (complexidade O(log n)) e o resultado é um algoritmo O(n log n), no par do campo com os demais.
A grande sacada do heap sort é que a árvore binária não é criada de fato. Ela existe implicitamente; cada elemento da lista é relacionado a um ponto da árvore virtual, conforme sua posição:
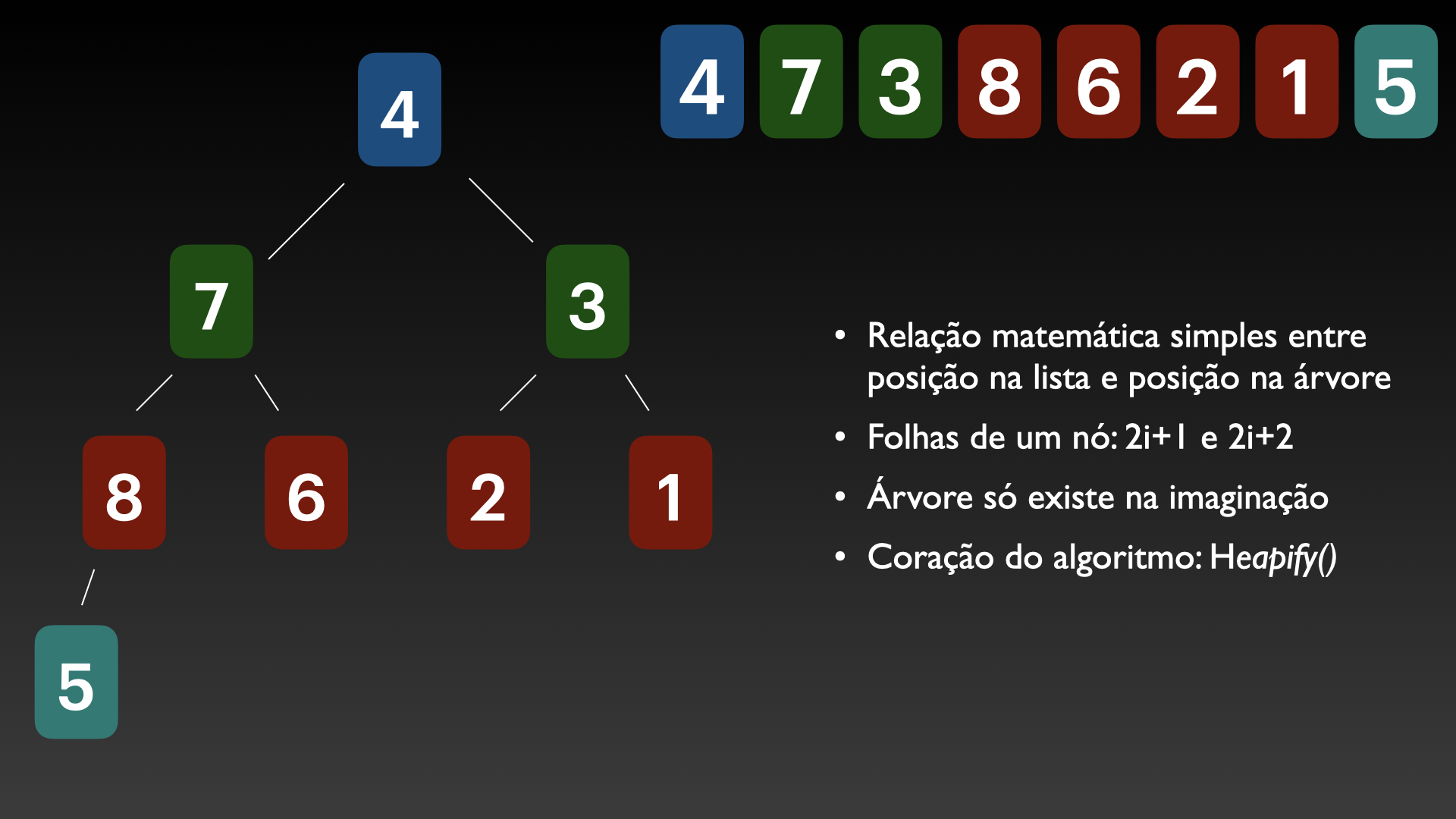
É fácil determinar onde cada elemento da lista está na árvore virtual, e quais são suas folhas, com base na posição linear na lista. Por exemplo, as folhas do 4º elemento são os 8º e 9º — bastou multiplicar 4 por 2.
A árvore binária deve ser arranjada de forma que o elemento de valor mais alto ocupe o nó do topo. Isto deve ser verdade para todas as sub-árvores: se um galho for cortado fora, o nó de topo dele ainda deve conter o elemento mais alto de toda a parte destacada.
O coração do heap sort é um algoritmo denominado heapify() na literatura sobre o tema. A princípio ele faz uma coisa bem simples: dado um nó e suas duas folhas, se houver uma folha de valor mais alto, ela troca de lugar com o nó.
Porém, se a folha é mexida, e houver uma sub-árvore pendurada naquela folha, a sub-árvore pode ter ficado "estragada", ou seja, o topo dessa sub-árvore pode não conter o respectivo valor mais alto.
Para consertar isso, o heapify() é invocado recursivamente sobre a sub-árvore. Uma vez que o heapify() é recursivo, isto garante que os elementos de menor valor vão sendo empurrados para baixo.
Mas falta ainda um mecanismo para empurrar os valores altos para cima, que é o seguinte. No início do heap sort, o heapify() é executado sobre todos os nós da árvore, de baixo para cima, da direita para a esquerda.
Isto garante que os valores altos vão subir, um nível de cada vez. E a recursividade de cada heapify() garante que os elementos baixos vão descer.
Terminado o arranjo, o topo da árvore (que é o primeiro elemento da lista) contém o valor mais alto. Ele é transferido para o fim da lista, que é o seu lugar de direito.
Segue uma animação que tenta ilustrar o arranjo inicial, e o uso do valor mais alto para preencher a lista:
Neste ponto a árvore perdeu uma folha, pois a parte não-ordenada da lista ficou um elemento mais curta.
Quando o elemento mais alto foi sacado, o topo da árvore foi ocupado por outro elemento qualquer, de valor baixo. A árvore está "estragada", mas para arrumá-la, basta executar heapify() uma vez mais, sobre o nó do topo:
A cada ciclo de arranjar a árvore e sacar seu valor mais alto, a lista encurta e a árvore fica menor.
Não vou mentir, sofri bastante para entender este algoritmo, e tive de consultar diversas fontes para entender como ele funciona, e então implementá-lo corretamente:
def heapify(tamanho, topo):
folha_esq = topo * 2 + 1
folha_dir = folha_esq + 1
maior = topo
# Determina quem é maior, entre topo e folhas
if folha_esq < tamanho and lista[folha_esq] > lista[maior]:
maior = folha_esq
if folha_dir < tamanho and lista[folha_dir] > lista[maior]:
maior = folha_dir
if maior != topo:
# Troca
lista[maior], lista[topo] = lista[topo], lista[maior]
# Recursão no galho afetado pela troca
heapify(tamanho, maior)
# Primeiro arranjo
tamanho = len(lista)
i = len(lista) // 2 - 1
while i > 0:
heapify(tamanho, i)
i -= 1
while tamanho > 1:
# Conserta árvore
heapify(tamanho, 0)
# Saca topo da árvore
lista[0], lista[tamanho - 1] = lista[tamanho - 1], lista[0]
tamanho -= 1
print(lista)
Numa árvore binária, metade dos elementos sempre são folhas terminais. Por conta disso, o arranjo inicial só precisa chamar heapify() sobre os elementos da primeira metade da lista. Esta pequena otimização já foi aplicada no código acima.
Além de ser O(n log n), esse algoritmo tem a vantagem de não ter condicionantes (e.g. o pivô do Quicksort) e não precisa de memória extra como o merge sort. Por outro lado, é complexo e tipicamente menos eficiente que os demais, sendo por isso relativamente pouco usado. Esta thread discute um problema do heapsort.
Existem algoritmos mais novos de sort, que são basicamente combinações das técnicas clássicas, visando explorar alguma localidade, ou seja, alguma condição comumente observada no ambiente em que o algoritmo opera.
Já citamos antes que o algoritmo por inserção é utilizado como auxiliar de quicksort na ordenação de pequenas frações da lista, pois nesta condição ele é mais rápido, mesmo sendo quadrático. Isto acontece porque a CPU (incluindo o cache de memória, que reside dentro da CPU) é muito mais rápida que a memória. A condição necessária é a lista ordenada pelo sort de inserção caber inteiramente no cache.
Diferentes computadores têm CPUs com diferentes velocidades e caches, então o ponto ótimo também é diferente. Implementações que tentam ser genéricas delegam listas relativamente curtas ao sort por inserção, entre 4 e 20 elementos.
O Merge Sort é um algoritmo "caro" devido à necessidade do dobro de memória para armazenar uma cópia da lista. O algoritmo BlitSort é um híbrido de merge sort e quick sort, usando uma área fixa e relativamente pequena de memória para a operação de merge. Novamente, a definição de "relativamente pequena" é uma localidade, varia de acordo com o computador em que ele vai rodar.