 Máquina de Turing
Máquina de Turing
Máquina de Turing
Máquina de Turing
Este artigo é uma homenagem ao Bitcho, que alega conhecer trocentras linguagens de programação, inclusive "Máquina de Touring" [sic].
O exemplo abaixo é uma máquina de Turing que incrementa um número binário a cada rodada. Sinta-se à vontade em apertar os botões e ver como (ou se) ela funciona.
A máquina de Turing é uma extensão do autômato finito, e tem importância enorme na ciência da computação.
Porém, enquanto o autômato finito é uma abstração extremamente útil no dia-a-dia do desenvolvimento de software, a máquina de Turing é um conceito essencialmente teórico. Apesar do nome, não se encontra máquinas de Turing para comprar. Pelo menos até onde se sabe, não é vantagem fabricar um computador na arquitetura de Turing; ele seria extremamente lento e difícil de programar.
A máquina de Turing (doravante TM, por brevidade) foi imaginada pelo cientista Alan Turing ainda nos anos 1930, antes mesmo da invenção dos computadores reais. Turing perguntou-se: o que é possível calcular-se por meio de uma máquina? Quais os problemas insolúveis para as máquinas? A TM foi o modelo usado para ajudar a responder estas questões.
Desde então, muitos outros cientistas imaginaram muitas outras máquinas computacionais, com variados graus de utilidade prática. Entre elas, estão os computadores que permeiam nossa vida hoje em dia.
Porém todas estas máquinas provaram ser equivalentes à TM. Um problema insolúvel na TM é insolúvel em qualquer máquina, real ou imaginária. A definição moderna de algoritmo é: aquilo que pode ser executado em uma TM (ou numa máquina equivalente à TM).
Lembrando sempre que esta é uma equivalência teórica: em se tratando de resolver problemas "solúveis", algumas máquinas são muito mais rápidas e fáceis de programar que outras.
Como você pode ter notado na máquina de exemplo do início do artigo, uma TM parece com um autômato finito (doravante FA, por brevidade). Assim como um FA, uma TM possui estado atual e uma tabela de transição de estados.
Para melhor entender as diferenças entre uma e outra, vamos primeiro listar os ingredientes essenciais de um FA:
O autômato é "burro" pois sua memória de trabalho se resume ao seu estado atual.
Um exemplo didático de autômato é uma máquina de vender refrigerante. É bem instrutivo imaginar os diversos estados da mesma (esperando dinheiro, recebeu dinheiro, dispensando lata, devolvendo dinheiro) e os eventos de entrada (depositando moeda, lata dispensada, botão de cancelamento pressionado).
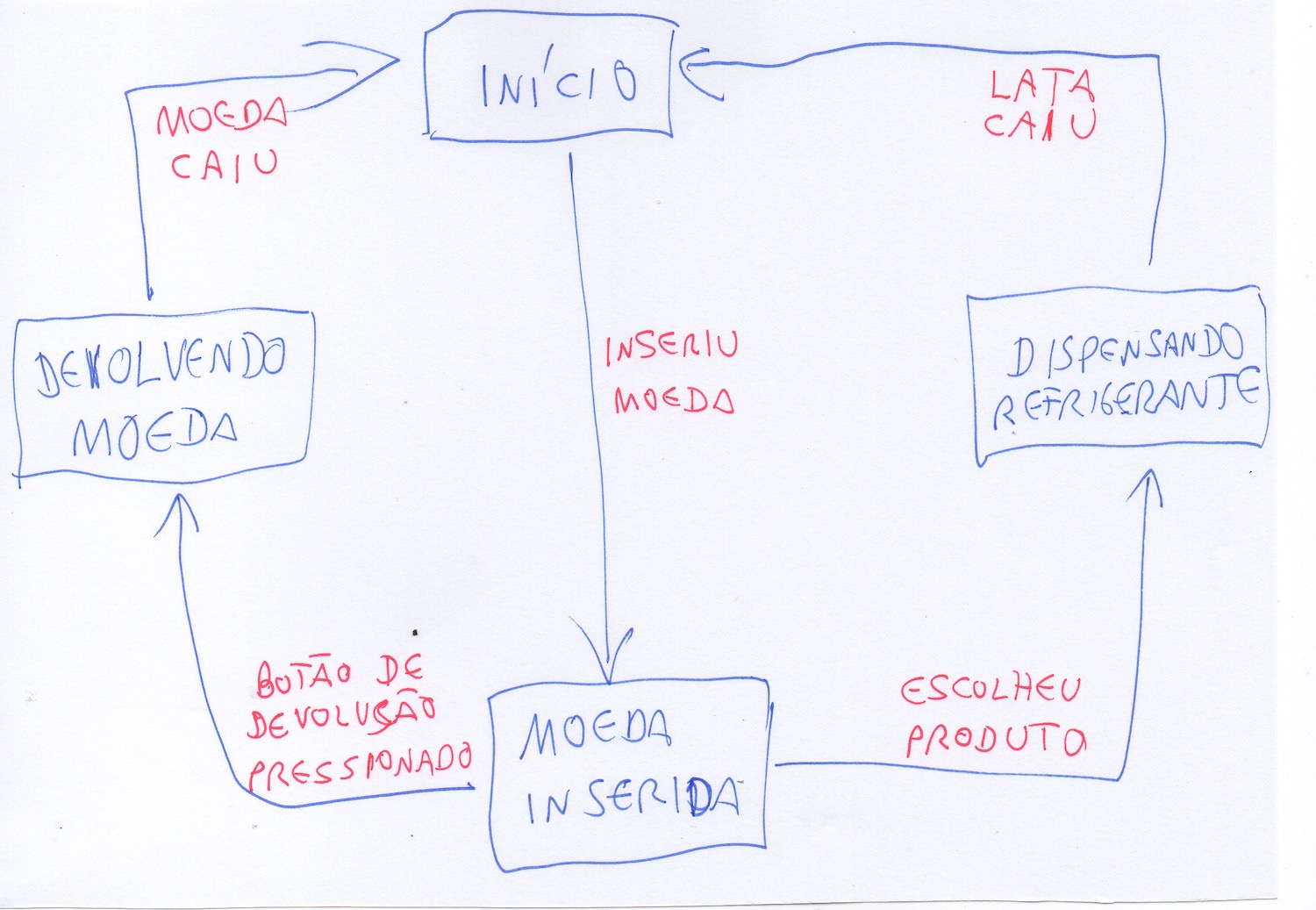
Nesta máquina, faz sentido ignorar transições imprevistas. Por exemplo, se o usuário pressionar o botão de cancelamento sem ter inserido moeda, ou depois da lata já ter sido servida, não devemos reagir.
Outro exemplo didático é um FA que implementa uma expressão regular. Por exmeplo, a expressão "^B[AEIOU]L[AEIOU]$" reconhece palavras de 4 letras como BALA, BELO, BILU, etc.
Uma "fita" ou string de símbolos é consumida pela FA de forma sequencial. O alfabeto de entrada seria literalmente o alfabeto de A a Z mais um símbolo "nulo" que demarca os limites da palavra.
![Figura 2: Autômato finito correspondente à expressão regular ^B[AEIOU]L[AEIOU]A$](touring/maquinaer.jpg)
Num autômato que reconhece expressão regular, uma transição inesperada significa que a string não deve ser aceita, e o FA deve ir para um estado terminal de "erro" ou "string rejeitada".
Achei importante descrever um FA que processe uma fita de entrada em vez de uma seqüência de eventos, porque a literatura sobre TM gira em torno das fitas. A TM estende o FA com os seguintes elementos:
A TM possui memória de trabalho ilimitada, pois além do estado atual, há uma fita de comprimento infinito que pode ser gravada. Além disso a fita pode ser lida e/ou gravada de forma não-sequencial, movendo a cabeça à vontade.
Já que a TM é mais poderosa que o FA, é tranquilo implementar um FA usando TM. O exemplo abaixo implementa aquela expressão regular "^B[AEIOU]L[AEIOU]$", gravando cifrões na medida em que a palavra é reconhecida. Se a string for boa, a máquina pára (*) no último item da tabela de transições. Se a string não for boa, a máquina pára intempestivamente.
(*) Dane-se a reforma ortográfica de 2008!
A fita da máquina a seguir vai ser rejeitada:
Tenho de confessar que cometi uma pequena desonestidade intelectual. Implementei as TM de exemplo com alguns recursos a mais, em relação à TM "baunilha":
O primeiro item só tem valor estético. Já os dois últimos itens efetivamente estendem a TM original, tornando-a mais poderosa e mais fácil de programar.
Mas é importante relembrar que uma TM "estendida" não é inerentemente mais poderosa que a TM baunilha. A TM-baunilha é capaz de simular qualquer TM estendida, ou qualquer outra máquina computacional ‐ ainda que mais lentamente. (Isto foi descoberto ao longo do tempo, conforme o próprio Turing e outros cientistas tentaram encontrar um modelo inerentemente mais poderoso que a TM.)
Mais importante ainda: sempre é possível escrever um "compilador" que converta mecanicamente o programa de uma TM estendida para uma TM-baunilha. (Geralmente é assim que se prova que uma máquina é Turing-completa: se qualquer programa da máquina X pode ser convertido para TM e vice-versa, a máquina X é equivalente à TM.)
Por outro lado, se tirarmos qualquer recurso da TM-baunilha, ela deixa de ser "Turing-completa". A TM é o modelo mais simples, não há nada sobrando, por isso mesmo é objeto de maior interesse teórico.
Quem conhece um pouco de processadores e assembler, reconhece prontamente alguns paralelos da TM com uma CPU moderna. O estado atual é análogo a um registrador, a fita é análoga à memória RAM, a tabela de transição é análoga a um programa.
Uma limitação bem patente da TM é o "programa" fixo, imutável. Porém, o próprio Turing imaginou uma TM que carregue os possíveis estados e transições a partir da fita, no início da operação. Tal máquina é capaz de executar qualquer algoritmo. Esta é a Máquina Universal de Turing, doravante UTM.
O fato do programa residir na fita abre outra possibilidade: podemos escrever programas que analisam outros programas. Em particular, um programa pode analisar a si mesmo. O que nos conduz ao...
É muito fácil deduzir se um autômato finito (FA) vai parar ou vai continuar trabalhando para sempre, dada uma fita de entrada ou seqüência de eventos. Esta análise pode ser feita inclusive por meios mecânicos i.e. podemos conceber uma TM que analise um FA e responda corretamente se este último pára ou não.
Por exemplo, é fácil ver que nosso FA que vende refrigerante nunca pára, porque ele não tem estados terminais e ignora transições inesperadas. Já nosso FA de expressão regular sempre pára, independente da fita de entrada.
E no caso de uma máquina de Turing? É possível analisar algoritmicamente uma TM e dizer com 100% de certeza se ela pára? Este é o famoso "Problema da Parada" ou "Halting Problem". E Turing provou que "não": uma TM não pode afirmar com certeza se outra TM pára.
A prova é por contradição. Suponha o seguinte programa em "Javascript":
var i = function (j) {
if (programa_para(j, j)) {
while (true);
} else {
return true;
}
}
i(i);
No programa acima, a função programa_para(A, B) alega ser capaz de responder à pergunta "o programa A pára se alimentado com a fita B?". Se tal função existisse, ela seria capaz de analisar a si mesma, ou a uma rotina que chame esta função. Isto causa uma contradição:
De certa forma, o trabalho de Turing estendeu os trabalhos de Gödel e Cantor. Nos labores da "Teoria da Incompleteza", Gödel descreveu um método de codificar axiomas e teoremas matemáticos usando números naturais — os chamados "números de Gödel". Também divisou meios de, por exemplo, provar um teorema de forma mecânica, fazendo apenas operações aritméticas sobre o número de Gödel do teorema.
Para provar que isto é possível (não necessariamente eficiente), Gödel criou o conceito de função primitiva recursiva. Por exemplo, os axiomas de Peano para multiplicação constituem uma função primitiva recursiva:
a . 0 = 0 a . b = a + (a . (b - 1))
Multiplicação de 3×2 usando apenas os axiomas:
3 . 2 3 + 3 . 1 3 + 3 + 3 . 0 3 + 3 6
Não é uma forma eficiente de multiplicar dois números, mas funciona, e sabemos de antemão quanto trabalho vai dar.
A intuição nos diz que "função primitiva recursiva" é sinônimo de função computável — um problema que uma máquina pode resolver. E na maioria das vezes esta intuição está correta.
Porém, o trabalho teórico em torno da Máquina de Turing (TM) descobriu um nicho: funções computáveis que não são primitivas recursivas. Um exemplo bem conhecido é a Função de Ackerman, que é bem fácil de implementar, mas cuja profundidade de recursão cresce explosivamente, e não pode ser prevista de antemão.
Um outro exemplo é o "Jogo do Castor Ocupado" ou Busy Beaver Game. A ideia do jogo é construir uma TM que, dados os símbolos ('0', '1') e um número fixo de estados, grave o máximo de símbolos '1' na fita, mas ainda pare. O busy beaver abaixo tem 4 estados e 8 transições:
A propósito, o busy beaver acima é o "campeão" de sua classe (4 estados não-terminais), pois escreve 13 símbolos '1' na fita. Todos os demais ou escrevem menos símbolos, ou trabalham menos passos.
Obviamente o busy beaver em si é computável, você pode vê-lo rodar. Se teve paciência de esperar, constatou que ele pára após uma centena de passos.
Porém, a previsão do comportamento do busy beaver é incomputável. Não é possível calcular quantos passos um busy beaver vai trabalhar, nem quantos '1' ele vai gravar na fita, nem achar o busy beaver campeão para um certo número de estados. Procurar o "campeão" envolve descartar os candidatos a busy beaver que nunca param, e conforme vimos no "Problema da Parada", não é possível determinar mecanicamente se uma TM pára.
O único jeito de descobrir o que um busy beaver faz, é colocando para rodar — e rezar para que ele pare. Quando o número de estados é pequeno, ainda é viável analisar humanamente todas as possibilidades e achar o "campeão".
A máquina de Turing é difícil de programar, por dois motivos principais:
Von Neumann foi outro cientista que imaginou máquinas computacionais. Porém, diferente de Turing, Von Neumann construiu um computador de verdade, o EDVAC. Isto conduziu a um modelo muito mais fácil de programar:
Uma variante é a arquitetura Harvard, nome herdado de outro computador ancestral, o Harvard Mark I. Nesta arquitetura, o programa é alojado numa memória separada. É popular em microcontroladores, onde o programa é gravado em flash (ROM).
Todos os computadores modernos seguem a arquitetura Von Neumann ou Harvard. Recursos adicionais das máquinas, como registradores, pilhas, etc. existem para facilitar a programação e/ou aumentar o desempenho, mas a essência continua sendo a mesma.
Quase ninguém programa em linguagem de máquina. Geralmente se usa uma linguagem de programação. Cada linguagem de programação é uma "máquina virtual", geralmente de nível mais alto que a máquina real, mais fácil de programar, etc., porém com as mesmas limitações fundamentais da máquina de Turing e da máquina real em que o programa vai afinal rodar.
Uma máquina Von Neumann, ou a máquina virtual implementada por uma linguagem de programação, pode ou não ser Turing-completa. Vai depender do conjunto de instruções que esta máquina aceita.
Para que uma máquina Von Neumann seja Turing-completa, ela deve ser capaz de:
Uma linguagem que possua "if" e "goto" é muito provavelmente Turing-completa. Ela se distingue de um autômato finito (FA) porque pode tomar uma decisão com base num valor de RAM, que quiçá ela mesma gravou.
Às vezes é interessante que uma máquina não seja Turing-completa. Quando usamos FA em programação, visamos limitar a complexidade. Queremos ter certeza que o programa (ou aquela parte do programa) sempre pára e/ou nunca assume um estado inconsistente.
As linguagens de script do Bitcoin e do Ethereum (com uso mais difundido neste último) são deliberadamente não-Turing-completas. Para resumir, elas não possuem while(), possuem apenas for(x:0..n). O número de ciclos é limitado a "n", e o tempo de execução de um script pode ser estimado mecanicamente.
No Ethereum, o script tem de pagar um valor proporcional à sua complexidade para ser executado, então é preciso estimar essa complexidade de antemão para fazer a cobrança. E isto só é possível se a linguagem de script não for Turing-completa.
A complexidade de um algoritmo costuma ser medida pelo esforço realizado, em função do volume de dados de entrada. Quanto mais dados, mais tempo o algoritmo leva para realizar a tarefa.
Por exemplo, procurar uma letra numa string de comprimento "n" custa no mínimo "n" comparações: uma por letra da string. O esforço cresce linearmente com o tamanho da string. Expressamos esta complexidade como O(n). O tempo que o algoritmo demora para rodar cresce linearmente com "n".
Também podemos avaliar a complexidade do algoritmo em função do espaço que ele ocupa na RAM, ou mesmo em circuito no caso de algoritmos implementados ou acelerados em hardware. Existem problemas em que se pode diminuir o tempo à custa de mais espaço ou vice-versa.
Ambas as grandezas, tempo e espaço, são importantes na hora de avaliar um algoritmo, porém a análise "Big O" costuma focar muito mais no tempo.
A "função" O() não é realmente uma função, mas sim um conjunto de funções. O(n) é a família de funções cujo comportamento é predominantemente linear conforme cresce o valor de "n". 2n, 300n, 5n+1000, 0.5n-3, todas estas funções são da mesma família.
No curso deste texto, já visitamos dois problemas indecidíveis ou incomputáveis: o Problema da Parada, e descobrir o melhor Castor Ocupado. É matematicamente provado que existem muito mais problemas insolúveis que solúveis para um computador.
Logo abaixo dos problemas incomputáveis, temos os problemas de complexidade fatorial O(n!) ou exponencial ou O(2^n). No geral, são considerados problemas intratáveis, pois demoram muito para resolver numa máquina real.
Num problema verdadeiramente intratável, nem mesmo a sorte pode ajudar. Conferir se uma possível solução é a correta demora tanto quanto procurar por ela.
Em seguida, temos a classe NP. Os problemas NP podem ter complexidade fatorial ou exponencial, portanto ainda podem ser intratáveis. Porém uma possível solução pode ser conferida mais facilmente, em tempo polinomial. (Vou explicar melhor o "polinomial" logo adiante.)
Por exemplo, imagine o seguinte algoritmo (bem burro) de ordenação de cartas de baralho:
Este é o "BogoSort". A complexidade deste algoritmo é fatorial (O(n!)) pois há 52! possibilidades de embaralhar um baralho. (52! é um número de 68 dígitos.)
Uma variante denominada "BozoSort" faz um pouco diferente: em vez de embaralhar tudo, apenas troca duas cartas aleatórias de lugar. Não se tem certeza da complexidade, mas supõe-se que também fica em torno de O(n!).
Porém é muito fácil conferir se o baralho está em ordem, é uma tarefa de complexidade linear O(n). Se você aplicar o BogoSort ou o BozoSort em um baralho novo, ele roda em O(n) e termina rapidamente.
Claro, qualquer criança consegue colocar um baralho em ordem, então é óbvio que deve existir algoritmos de ordenação mais eficientes que o BogoSort. Por outro lado, existem problemas NP genuinamente intratáveis, que têm resistido a todas as tentativas de otimização.
Por exemplo, o "Problema do Caixeiro Viajante", que consiste em determinar a rota mais curta para visitar um rol de cidades. É possível elaborar um algoritmo para resolver este problema, porém ele não será mais rápido do que ficar tentando combinações aleatórias.
O "Caixeiro Viajante" é especial em outros aspectos. Ele é um problema NP-completo. Os problemas NP-completos pertencem a uma classe à parte. É possível converter qualquer problema NP para um problema NP-completo. Se, algum dia, alguém encontrar um algoritmo eficiente para resolver um problema NP-completo, todos os problemas NP "caem" junto.
Uma propriedade peculiar do Caixeiro Viajante é admitir soluções sub-ótimas. Achar a rota mais curta é um problema NP-completo, mas os caixeiros-viajantes não deixam de viajar por conta disso, certo? Se queremos uma rota razoavelmente boa, aceitando o risco dela não ser a melhor possível, há algoritmos eficientes para achá-la.
Outro problema NP-completo é a alocação de grades de matérias de uma escola, em função de um conjunto de regras (horários de trabalho dos professores, evitar aulas duplas ou triplas, evitar certas matérias em certos turnos, etc.) E é outro exemplo de problema que admite soluções quase-ótimas — afinal de contas, as escolas conseguem produzir grades a cada novo período letivo.
Dentro da classe de problemas NP, temos os problemas P, que têm solução em tempo polinomial: O(n), O(n^2), O(n^3) ou algo assim. Função polinominal é "n" elevado a alguma potência fixa. Ou seja, um problema P é um problema NP com solução em tempo polinominal.
Uma pergunta ainda não respondida: P=NP? ou seja, seria o conjunto P igual ao conjunto NP? A maioria dos cientistas da área acredita que não. Mas, como dissemos antes, se for encontrada uma solução eficiente para um problema NP-completo, significa que a) esse problema também é P; b) todos os demais problemas NP-completos também são P; c) todos os problemas NP também são P, uma vez que todo problema NP é conversível para algum problema NP-completo.
Um algoritmo O(n^3) trabalha em função do cubo da entrada: se há 1000 entradas, o algoritmo exerce um esforço proporcional a um bilhão de passos. Isso é bastante coisa, mas é melhor que complexidade exponencial ou fatorial. Uma função O(2^n) ou O(n!) acaba sempre ultrapassando uma função de expoente fixo, basta fazer "n" grande o bastante.
Um algoritmo O(n^2) bem didático é o Bubble Sort, um método de ordenação considerado ineficiente. Podemos implementar o Bubble Sort para um baralho de cartas:
O algoritmo acima executa umas 2500 comparações no máximo. É muita coisa, mas é muitíssimo melhor que 52! tentativas. Um erro comum é dizer que O(n^2) é "exponencial". Ele é quadrático, o que é bem diferente. 52^2 é igual a 2704, 2^52 é igual a 4503599627370496.
Também é errado dizer que um algoritmo O(n^2) ou O(n^3) é inerentemente ruim para uso prático. Por exemplo, o melhor algoritmo conhecido para multiplicação de matrizes tem peso O(n^2.78). Para quem precisa multiplicar matrizes grandes, o jeito é comprar um computador mais rápido.
Mas, em se tratando de ordenação, existem algoritmos melhores que O(n^2). O algoritmo "Shell sort" é O(n^1.25). Os algoritmos "Quicksort" e "Merge Sort" de uso corrente são O(n log n). (É matematicamente provado que O(n log n) é a complexidade mínima possível para ordenação.)
Já vimos que o algoritmo de procura de um caractere dentro de uma string é linear — O(n). O algoritmo eficiente de procura numa lista ordenada (ou numa árvore ordenada) é a busca binária, cuja complexidade é sublinear — O(log n).
Por exemplo, quando você procura por uma página de um livro, não vai ficar folheando as páginas uma a uma. Vai abrir o livro mais ou menos na metade. Se a página encontrada for maior que a desejada, vai repetir o procedimento com a primeira metade, recursivamente.
Num livro de 1000 páginas, basta 10 ou 11 operações. Para achar a página 666, basta abrir o livro nas páginas 500, 750, 625, 687, 656, 671, 664, 667, e neste ponto é mais fácil folhear pois sobraram apenas 3 páginas.
O "milagre" do algoritmo acima é que ele funciona para valores muito grandes de "n". Num livro hipotético de um bilhão de páginas, conseguiríamos achar qualquer página em no máximo 30 operações.
Melhor que um algoritmo logarítimico, só mesmo um algoritmo de tempo constante ou O(1), cuja complexidade não varia em função da entrada.
Um algoritmo de multiplicação implementado em software é O(log n), onde "n" é a soma dos tamanhos dos números envolvidos. Em hardware, a multiplicação pode ser O(1), à custa de um circuito mais complexo que faça somas em paralelo. Existe uma transferência de complexidade do tempo para o espaço, que neste caso é vantajosa.